
Pracujesz już z jakąś bazą danych jakiś czas, ale nadal spotykasz dziwne klauzule, których nie rozumiesz? W tym wpisie przedstawiam szybki przegląd z klauzul dookoła SELECT’a dostępnych w Snowflake’u. Nie jest to szczegółowy opis każdej z nich, ale raczej zajawka mająca na celu poszerzenie świadomości dostępnych możliwości.
Poniżej lista wszystkich elementów składni SELECT w kolejności, w jakiej muszą być pisane.
[ WITH ... ]
SELECT
[ TOP <n> ]
...
[ INTO ... ]
[ FROM ...
[ AT | BEFORE ... ]
[ CHANGES ... ]
[ CONNECT BY ... ]
[ JOIN ... ]
[ LATERAL ... ]
[ MATCH_RECOGNIZE ... ]
[ PIVOT | UNPIVOT ... ]
[ VALUES ... ]
[ SAMPLE ... ] ]
[ WHERE ... ]
[ GROUP BY ...
[ HAVING ... ] ]
[ QUALIFY ... ]
[ ORDER BY ... ]
[ LIMIT ... ]SELECT jest pogrubiony bez nawiasów klamrowych, żeby wyszczególnić go jako jedyny obowiązkowy element, bez którego nic z bazy nie wyciągniesz.
Nawiasy klamrowe otaczają elementy opcjonalne, ale też zamykają w logiczną całość elementy zależne od siebie.
Klauzula WITH
WITH na samym początku służy do definiowania zapytań CTE (Common Table Expression / Wspólne Wyrażenia Tablicowe). Możesz w nich tworzyć kolejne zapytania SELECT i wykorzystywać je wielokrotnie w późniejszym kodzie. Podczas wykonywania całego zapytania wszystkie CTE tworzą coś na zasadzie tymczasowego widoku, który jest obliczany jednorazowo i istnieje tylko na czas wykonywania zapytania.
WITH cte_name_1 AS (
SELECT O_ORDERKEY
,O_CUSTKEY
,O_ORDERDATE
,O_ORDERPRIORITY
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.ORDERS
WHERE O_ORDERDATE >= '1998-01-01'
)
SELECT c1.O_ORDERKEY
,c1.O_CUSTKEY
,c1.O_ORDERDATE
,c1.O_ORDERPRIORITY
,li.L_PARTKEY
,li.L_QUANTITY
,li.L_EXTENDEDPRICE
FROM cte_name_1 c1
INNER JOIN SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.LINEITEM li
ON c1.O_ORDERKEY = li.L_ORDERKEY;SELECT
W tej klauzuli definiujesz kolumny, które chcesz odczytać oraz ich transformacje.
Do wykonania zapytania do silnika bazy danych wystarczy sam SELECT, choćby w sytuacji, gdy chcesz się dowiedzieć jaka data będzie za 487 dni wystarczy, że wykonasz poniższe zapytanie.
SELECT DATEADD(DAY,487,CURRENT_DATE());..SELECT TOP <n>
Bardzo prosta klauzula, bo po prostu definiuje ile wierszy baza danych ma zwrócić.
Poniższy przykład ma zwrócić pierwsze 10 rekordów.
SELECT TOP 10 *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;Zgodnie z powyższym nie oczekuj jednak, że będzie to rzeczywiście pierwsze 10 rekordów zapisanych do bazy danych. Pewność zwrócenia pierwszych iluś rekordów zgodnie z jakąś definicją da tylko dodanie klauzuli ORDER BY, która posortuje najpierw wszystkie wyniki pod spodem i z tego zbioru zwróci wybraną liczbę wierszy.
SELECT TOP 10 *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER
ORDER BY C_ACCTBAL;INTO
Przy tej klauzuli wychodzi pochodzenie Snowflake’a :). Założyciele Snowflake’a pracowali wcześniej w Oracle’u i wiele konwencji z Oracle’a przenieśli bezpośrednio właśnie do Snowflake’a.
INTO pozwala zapisać wyniki zapytania do zmiennych.
Zauważ, że tutaj kod jest bardziej skomplikowany i został opakowane w dodatkowe słowa kluczowe, a cała ta struktura nazwana jest blokiem. Jeśli masz już doswiadczenie z bazami Oracle, to pewnie dobrze znasz tą składnię. Jeśli nie i chcesz dowiedzieć się o niej więcej zajrzyj tutaj, by doczytać więcej o blokach w Snowflake’u.
DECLARE
var_comment VARCHAR;
var_priority VARCHAR;
BEGIN
SELECT TOP 1
O_COMMENT
,O_ORDERPRIORITY
INTO :var_comment
,:var_priority
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
WHERE O_ORDERKEY = 1;
RETURN
'Order priority is ' || var_priority || ', and comment is ' || var_comment;
END;FROM
Tutaj wymieniasz tabele, widoki lub funkcje tabelaryczne z których chcesz wyciągnąć dane. I w sumie to wszystko 🙂
Jeśli masz już wybrany kontekst bazy danych i schematu w worksheet’cie to możesz posługiwać się samą nazwą tabeli, jednak najlepszą praktyką jest posługiwanie się pełnym adresem obiektu, który chcesz odczytać.
SELECT *
FROM baza_danych.schemat.widok;Wewnątrz klauzuli FROM istnieje sporo dodatkowych możliwości do wykorzystania.
..FROM […] AT | BEFORE
AT i BEFORE dają możliwość wykorzystania podróży w czasie w historii tabeli (Time Travel).
Poniższy przykład przedstawia zapytanie do stanu tabeli X z dnia 2023-12-28 o godzinie 15:00. Jeśli ustawienia Time Travel na tej tabeli były zdefiniowane w taki sposób, że umożliwiają przechowywanie jej stanów wystarczająco długo, to niezależnie od tego do ilu zmian doszło w danych tej tabeli, to i tak będziesz w stanie odczytać tę tabelę z danego momentu.
SELECT *
FROM baza_danych.schemat.tabela
AT(TIMESTAMP => '2023-12-28 15:00:00'::TIMESTAMP);Kolejny przykład zwraca stan tabeli sprzed wykonania zapytania z id '01b1fd3b-0001-9d31-0000-00052ff2e01d'.
SELECT *
FROM baza_danych.schemat.tabela
BEFORE(STATEMENT => '01b1fd3b-0001-9d31-0000-00052ff2e01d');Snowflake umożliwia podróże w czasie od 0 do aż 90 dni zależnie od rodzaju konta i ustawień tabeli.
..FROM […] CHANGES
Faja rzecz, jak chcesz sprawdzić co się zmieniło w stanie tabeli w „międzyczasie”. Porównałbym to do sprawdzania różnic między gałęziami w Git’cie, bo ta funkcjonalność nie pokaże Ci zmian, tylko różnice w tabeli między dwoma stanami w czasie.
Żeby móc z tej funkcjonalności parametr CHANGE_TRACKING tabeli musi mieć wartość TRUE. Dodatkowo, ta funkcja bazuje na Podróżach w czasie, więc te też muszą być możliwe na wybranej tabeli.
Poniżej przykładowa składnia, ale nie będę się wgryzać w szczegóły. Póki co po więcej odsyłam do dokumentacji Snowflake’a, a jak przyjdzie pora może opiszę to kiedyś po swojemu 🙂
SELECT *
FROM t1
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => '2024-01-31 23:00:00.000');..FROM […] CONNECT BY
Bardzo ciekawa klauzula, która pozwala Ci na dość prosty kod, który automatycznie robi zapętlonego self-join’a. Przydaje się przede wszystkim do przetwarzania danych hierarchicznych.
Taki sam efekt jak pisząc proste zapytanie zawierające CONNECT BY możesz osiągnąć pisząc całkiem zgrabne CTE (ale o tym kiedy indziej).
Dla przedstawienia odpowiedniego przykładu stworzyłem taką tabelę zawierającą hierarchię kategorii produktów w sklepie.
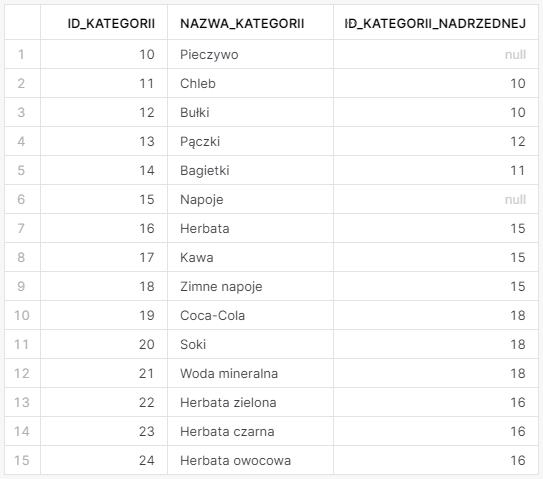
Żeby osiągnąć taki rezultat…

…wystarczy uruchomić taki kod.
SELECT SYS_CONNECT_BY_PATH(NAZWA_KATEGORII, ' -> ') AS HIERARCHIA_KATEGORII
,ID_KATEGORII
,ID_KATEGORII_NADRZEDNEJ
FROM KATEGORIE_PRODUKTOWE
START WITH ID_KATEGORII_NADRZEDNEJ IS NULL
CONNECT BY
ID_KATEGORII_NADRZEDNEJ = PRIOR ID_KATEGORII
ORDER BY ID_KATEGORII;..FROM […] JOIN
INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN, CROSS JOIN, NATURAL JOIN. Podstawy łączenia tabel. Można o nich pisać dużo i długo.
| Złączenie | Diagram | Opis |
|---|---|---|
| INNER |  | Złączenie wewnętrzne. Zwraca jedynie wiersze, gdzie lewa i prawa strona złączenia ma pasujące wartości. |
| LEFT |  | Złączenie lewostronne. Zwraca wszystkie wiersze z lewej tabeli i tylko pasujące dane z prawej tabeli. |
| RIGHT |  | Odwrotność LEFT JOIN’a. |
| FULL OUTER |  | Złączenie pełne. Zwraca wszystkie wiersze z obu tabel. Wartości kolumn z tabel, gdzie warunek złączenia nie jest spełniony są puste (NULL). |
| CROSS |  | Złączenie kartezjańskie. Umożliwia złączenie każdego wiersza z lewej tabeli z każdym wierszem z prawej tabeli. |
| NATURAL | Natural to „dodatkowa” opcja możliwa do dodania do wszystkich poprzednich typów złączeń. Złączenie następuje automatycznie na kolumnach o tej samej nazwie. Jeszcze nie spotkałem się z wykorzystaniem takiego złączenia w pracy. |
Poniżej przedstawiam LEFT JOIN, a po więcej póki co zapraszam do dokumentacji 😉
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS o
LEFT JOIN SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER c
ON o.O_CUSTKEY = c.C_CUSTKEY;..FROM […] LATERAL
LATERAL przydaje się w sytuacjach, gdy w kolumna zawiera listy wartości i chcesz przerobić na bardziej tabelaryczny wynik.
Przyjmijmy, że masz tabelkę jak poniżej, gdzie wartość rekordów jednej z kolumn to listy.
CREATE TRANSIENT TABLE x (id INT, value ARRAY);
INSERT INTO x (id) VALUES (1),(2);
UPDATE x SET value = ARRAY_CONSTRUCT('Raz','Dwa') WHERE id = 1;
UPDATE x SET value = ARRAY_CONSTRUCT('Uno','Dos') WHERE id = 2; 
Chcesz teraz, żeby każda wartość z kolumny VALUE była w odrębnym wierszu.
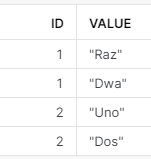
Wystarczy, że uruchomisz poniższy kod.
SELECT ID, y.VALUE
FROM x, LATERAL FLATTEN(INPUT => x.VALUE) AS y;Jeśli wykorzystasz LATERAL do złączenia 2 tabel funkcji FLATTEN, to Snowflake zrobi dokładnie to sami, co przy INNER JOIN. Nie kojarzę innych sensownych zastosowań złączenia LATERAL poza tym w połączeniu z funkcją FLATTEN. Jeśli kojarzysz inne sensowne zastosowania to się podziel 😉
..FROM […] MATCH_RECOGNIZE
To jest najbardziej skomplikowany element spośród wszystkich wymienionych w tym wpisie. MATCH_RECOGNIZE służy do rozpoznawania wzorców wierszy w zbiorze danych. Za pomocą tej funkcjonalności jesteś w stanie znaleźć konkretne wzorce występujące chociażby w danych giełdowych lub pogodowych. Wzorce identyfikuje się podobnie do pisowni wyrażeń regularnych i definiuje podobnie jak w klauzuli WHERE odpowiednio wewnątrz klauzul PATTERN() i DEFINE().
Żeby otrzymać taki rezultat, który przedstawia kiedy wartość rynkowa poszczególnych ETF’ów na przestrzeni przynajmniej kilku dni przyjmowała kształt litery „V”…
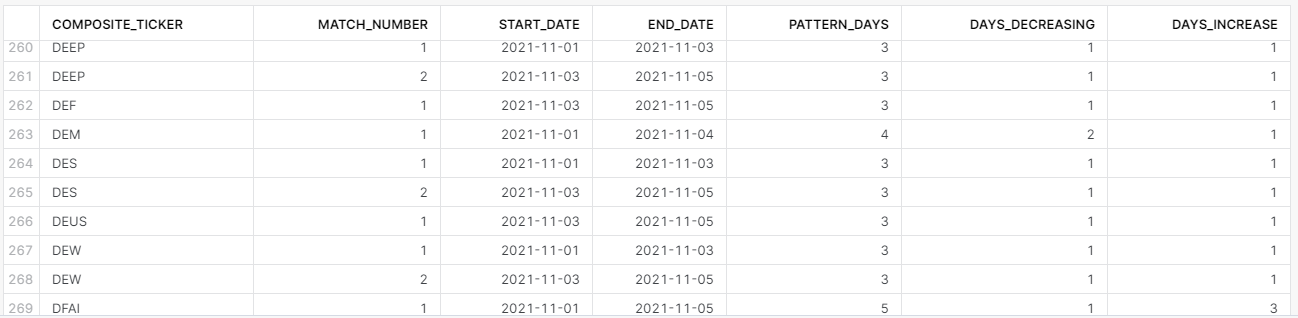
…możesz napisać takie zapytanie.
SELECT *
FROM etf_market_value
MATCH_RECOGNIZE(
PARTITION BY COMPOSITE_TICKER
ORDER BY AS_OF_DATE
MEASURES
MATCH_NUMBER() AS match_number
,FIRST(AS_OF_DATE) as start_date
,LAST(AS_OF_DATE) as end_date
,COUNT(*) as pattern_days
,COUNT(day_with_price_decrease.*) as days_decreasing
,COUNT(day_with_price_increase.*) as days_increase
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST day_with_price_increase
PATTERN(day_before_decrease day_with_price_decrease+ day_with_price_increase+)
DEFINE
day_with_price_decrease AS market_value < LAG(market_value)
,day_with_price_increase AS market_value > lag(market_value)
)
ORDER BY COMPOSITE_TICKER
,match_number;..FROM […] PIVOT | UNPIVOT
Aaachhhhh…. Tabele przestawne 🙂 Podstawowa funkcjonalność analityczna w Excelu. W SQL nie są to jednak najprzyjemniejsze kody do napisania.
PIVOT – tabela przestawna w SQL
Uciążliwą rzeczą w tabelach przestawnych jest to, że pisząc kod musisz dokładnie znać wartości kolumny, którą obracasz, żeby zdefiniować jakie nowe kolumny chcesz otrzymać.
WITH baza as (
SELECT O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
)
SELECT O_ORDERDATE, STATUS_P, STATUS_F, STATUS_O
FROM baza
PIVOT(sum(O_TOTALPRICE) FOR O_ORDERSTATUS IN ('P', 'F', 'O'))
AS przestawna (O_ORDERDATE, STATUS_P, STATUS_F, STATUS_O)
ORDER BY O_ORDERDATE;Jak widzisz, w kodzie dokładnie wypisałem wartości z kolumny O_ORDERSTATUS, które mają stać się kolumnami i zdefiniowałem ich nazwy, żeby móc się do nich odnieść w SELECT’cie.
No ok, ale co jeśli masz tabelę, w której dane napływają cały czas i musisz robić z każdej daty nową kolumnę?
Rozwiązaniem jest dynamiczny SQL (a jeszcze lepszym rozwiązaniem skorzystanie z makra w dbt), ale to temat na inny wpis 😉.
UNPIVOT – odwrócenie tabeli przestawnej
Wreszcie UNPIVOT – forma przywrócenia tabeli do poprzedniej struktury, przed jej przestawieniem.
Poniższa tabela PIVOTED_TABLE jest po prostu zapisanym wynikiem wcześniejszego zapytania z PIVOT.
SELECT *
FROM SALE.PUBLIC.PIVOTED_TABLE
UNPIVOT (TOTAL_SALES
FOR STATUS IN (STATUS_P, STATUS_F, STATUS_O));Przetestuj, popsuj, napraw 🙂
..FROM […] VALUES
VALUES to dość podstawowa klauzula, która umożliwi Ci stworzenie tablicy danych. No i po co ta tablica? Najczęściej wykorzystywana do zapisywania danych do tabeli w instrukcji INSERT. Czemu ją w ogóle wspominam tutaj? Bo równie dobrze możesz tworzyć zapytania do takiej tablicy, chociażby jak w poniższym przykładzie.
select column4::date as data
,$2::int as kolumna_druga
,$1::int as id_wiersza
,column3 as cyfra_slownie
from (VALUES
(1,2,'trzy','2023-12-31')
,(2,3,'cztery','2024-01-01')
,(3,4,'pięć','2024-01-02')
,(4,5,'sześć','2024-01-03')
);Mała chaotyczna zabawa z różnymi sposobami wybrania odpowiedniej kolejności, no i wyświetlenie kolumn w odpowiednim formacie (data, integer, varchar).
Zachęcam do zabawy. Czasem wykorzystuję ten sposób do przetestowania jakichś rozwiązań zamiast tworzyć fizyczne lub tymczasowe tabele.
..FROM […] SAMPLE
Jeśli najdzie Cię potrzeba pracy na losowym podzbiorze tabeli wykorzystaj właśnie klauzulę SAMPLE. Przydatne do testowania jakichś rozwiązań, gdy nie ma sensu zużywać zasoby na przetwarzanie całej ogromnej tabeli lub do tworzenia zbiorów na potrzeby modeli uczenia maszynowego.
Poniższe zapytanie zwróci losowy zbiór mniej więcej 10% całej tabeli.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
SAMPLE (10);Możesz też zażyczyć sobie od Snowflake’a dokładnej liczby wierszy lub podać seed, żeby wyniki były bardziej deterministyczne.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
SAMPLE ROW (10 ROWS);SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
SAMPLE (1) SEED(15);WHERE
Klauzula, która pozwala zrealizować jedną z najważniejszych zasad najlepszych praktyk pisania zapytań SQL: „Filtruj wcześnie”. WHERE pozwala filtrować dane z tabeli i widoków na poziomie poszczególnych rekordów.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
WHERE O_ORDERDATE > '1998-01-01';Nie zadziała na kolumnach zagregowanych funkcjami agregującymi ani na wynikach funkcji okna.
GROUP BY
No cóż… bez GROUP BY nie zagregujesz danych. Bardzo prosta i podstawowa klauzula przy wykonywaniu zapytań do kolumnowych baz danych, które zostały stworzone z myślą o optymalizacji zapytań agregujących dane.
SELECT O_ORDERDATE
,O_ORDERSTATUS
,COUNT(DISTINCT O_CUSTKEY) as distinct_customer_count
,COUNT(O_ORDERKEY) as order_count
,SUM(O_TOTALPRICE) as total_price
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
GROUP BY ALL;Możesz też wykorzystać GROUP BY do tego, by dostać unikatowe wiersze.
Poniższe 2 zapytania są sobie równoważne pod względem otrzymywanych wyników. Pod względem optymalizacji w Snowflake’u również się nie różnią – optymalizator w Snowflake’u zbuduje dla nich identyczne plany zapytania.
SELECT O_CUSTKEY
,O_CLERK
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.ORDERS
GROUP BY ALL;SELECT DISTINCT
O_CUSTKEY
,O_CLERK
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.ORDERS;PS: Jeśli chcesz poczytać więcej o GROUP BY ALL zajrzyj do mojego wcześniejszego wpisu.
..GROUP BY […] HAVING
HAVING jest jak WHERE, tylko działa na kolumnach zagregowanych funkcjami agregującymi.
Poniższy kod zwraca te statusy, gdzie liczba zamówień na danym statusie jest większa niż 300 tys.
SELECT O_ORDERPRIORITY
,COUNT(*) as COUNT_N
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
GROUP BY 1
HAVING COUNT_N > 300000;QUALIFY
Tej funkcjonalności wiele osób nie zna i też wiele silników baz danych nawet nie udostępnia. QUALIFY pozwala filtrować wyniki zapytania na wynikach funkcji okna.
Przykład zwraca wiersz zawierający dane pierwszego zamówienia każdego z klientów.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
QUALIFY ROW_NUMBER() OVER (PARTITION BY O_CUSTKEY ORDER BY O_ORDERDATE) = 1;ORDER BY
ORDER BY sortuje wyniki zapytania przed ich zwróceniem.
Ten przykład zwraca zamówienia posortowane od najnowszych do najstarszych, a jeśli mają tę samą datę zamówienia, to jeszcze „dosortowuje” rosnąco po wartości zamówienia.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
ORDER BY
O_ORDERDATE DESC
,O_TOTALPRICE;LIMIT
LIMIT jest bardziej rozbudowaną formą klauzuli TOP.
W prostej formie LIMIT 10 po prostu ograniczy wyniki to pierwszych odczytanych 10 rekordów…
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
ORDER BY O_ORDERKEY
LIMIT 10;… ale ma też kilka dodatkowych możliwości.
Po pierwsze możesz powiedzieć Snowflake’owi, żeby zwrócił pierwsze 10 rekordów, ale pominął przy tym pierwsze 3 za pomocą klauzuliLIMIT 10 OFFSET 3.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
ORDER BY O_ORDERKEY
LIMIT 10 OFFSET 3;Ale… jeśli chcesz zwrócić wszystkie wiersze poza pierwszymi 10, to przy LIMIT wpisz ” lub $$$$. Poniższe przykłady są sobie równoważne.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
ORDER BY O_ORDERKEY
LIMIT '' OFFSET 10;SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
ORDER BY O_ORDERKEY
LIMIT $$$$ OFFSET 10;
Dodaj komentarz