Wielokrotnie spotkałem się z opinią, że mam fajnie pracując z bazą danych w chmurze, bo nie muszę się przejmować optymalizacją kodu. Nic bardziej mylnego! Zrzucanie ciężaru zapytania jedynie na rozmiar klastra obliczeniowego Snowflake’a jest jak wyrzucanie pieniędzy. W każdej bazie danych istotny jest sposób, w jaki napiszesz swoje zapytanie, więc optymalizuj swój SQL!
Łatwe do wdrożenia 5 wskazówek, jak pisać szybszy i tańszy kod SQL w Snowflake’u (i innych bazach kolumnowych):
- Unikaj SELECT *
- Filtruj wcześnie i dobrze
- Agreguj wcześnie
- Transformuj późno
- Weryfikuj profile zapytań
1. Unikaj SELECT *
Ze względu na architekturę kolumnową Snowflake jest w stanie nie tylko efektywnie kompresować dane, ale też pomijać podczas odczytu kolumny, których nie potrzebujesz.
Jeśli tabela ma 50 kolumn, a Ty potrzebujesz jedynie 5 z nich – odczytaj jednie te potrzebne. Jak zauważysz poniżej Snowflake odczytuje jedynie tyle danych, ile musi.
Poniżej przykład pokazujący jak duże znaczenie ma ograniczanie liczby odczytywanych kolumn. Wszystkie poniższe zapytania są realizowane za pomocą klastra obliczeniowego w rozmiarze XS. Widać, że ograniczenie liczby kolumn przyspieszyło wykonanie zapytania 3x i wymagało od Snowflake’a odczytanie i wyświetlenie ponad 2x mniej danych.
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE BETWEEN '1998-05-01' AND '1998-05-31';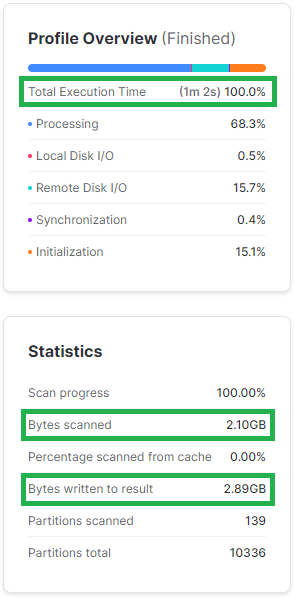
SELECT L_ORDERKEY
,L_PARTKEY
,L_QUANTITY
,L_EXTENDEDPRICE
,L_SHIPDATE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE BETWEEN '1998-05-01' AND '1998-05-31';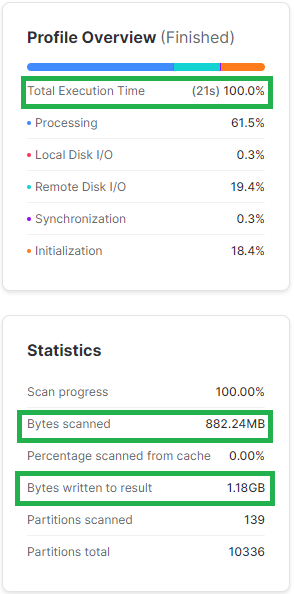
2. Filtruj wcześnie i dobrze
Im wcześniej wyfiltrujesz dane, tym mniej obciążysz klaster obliczeniowy. Snowflake przetwarza dane w pamięci, więc:
- Najpierw zapisuje je w pamięci RAM klastra obliczeniowego.
- Jeśli pamięć RAM jest zbyt mała pozostałe dane zapisywane są na dysku SSD klastra obliczeniowego. Nadal dość szybkie operacje, jednak wolniejsze niż RAM.
- Jeśli SSD nie wystarczy, to Snowflake korzysta bezpośrednio z bucketów dostawcy chmurowego (AWS, Azure, GCP). Tego chcesz uniknąć za wszelką cenę ze względu na koszmarną wydajność takich zapytań.
Żeby dobrze i efektywnie filtrować dane warto zwrócić uwagę na 2 aspekty:
2.1. Filtrowanie po dobrze sklastrowanych kolumnach
Nie zawsze jest to możliwe – w końcu zależy to od tego, jak tabela została zbudowane. Warto jednak wiedzieć która kolumna jest dobrze sklastrowana. Za dobrze sklastrowane kolumny możesz uznać takie, po których tabela jest posortowana. Idąc trochę głębiej – kolumny dobrze sklastrowane to takie, gdzie te same wartości nie są rozsiane losowo po wielu mikro-partycjach.
W poniższym przykładzie widać jak odpowiednie klastrowanie pozytywnie wpływa na wydajność filtrowania. Jeśli te dane są często filtrowane po obu kolumnach potencjalnie dobrym rozwiązaniem byłoby zastosowanie widoków zmaterializowanych. We wpisie o widokach zmaterializowanych znajdziesz też dokładniejszy opis jak czytać statystyki klastrowania kolumn.
SELECT L_ORDERKEY
,L_PARTKEY
,L_QUANTITY
,L_EXTENDEDPRICE
,L_SHIPDATE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE BETWEEN '1997-10-01' AND '1997-10-03';
--statystyki klastrowania kolumny L_SHIPDATE
SELECT SYSTEM$CLUSTERING_INFORMATION('SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM', '(L_SHIPDATE)');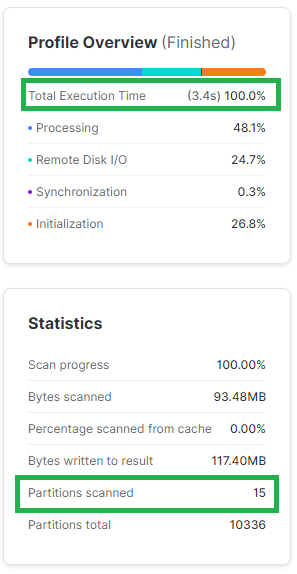

SELECT L_ORDERKEY
,L_PARTKEY
,L_QUANTITY
,L_EXTENDEDPRICE
,L_SHIPDATE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_COMMITDATE BETWEEN '1997-10-01' AND '1997-10-03';
--statystyki klastrowania kolumny L_COMMITDATE
SELECT SYSTEM$CLUSTERING_INFORMATION('SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM', '(L_COMMITDATE)');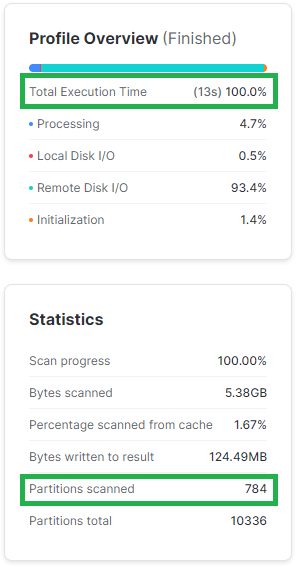

2.2. Nie stosuj funkcji na kolumnach, po których filtrujesz
Stosując funkcje na kolumnach, które wykorzystujesz do filtrowania zmuszasz Snowflake’a, żeby najpierw zaaplikował funkcję, lub jakąkolwiek inną transformację i dopiero później przefiltrował dane.
Lepszym rozwiązaniem jest tutaj przepisanie filtra w taki sposób, żeby dostosować wartości klauzuli WHERE do typu danych, w jakim jest zapisana kolumna.
Poniżej dość przerysowany przykład, gdzie kolumnę daty transformuję do formatu liczby. W niektórych firmach możesz się spotkać raczej z odwrotną sytuacją, gdzie data będzie w tabeli przechowywana jako INT. Widać, że edycja kolumny wpłynęła na znacznie większą liczbę odczytanych mikro-partycji co przełożyło się też na dłuższy czas zapytania.
SELECT L_ORDERKEY
,L_PARTKEY
,L_QUANTITY
,L_EXTENDEDPRICE
,L_SHIPDATE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE BETWEEN '1997-10-01' AND '1997-10-31';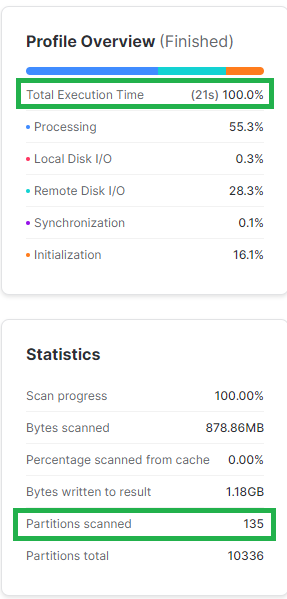
SELECT L_ORDERKEY
,L_PARTKEY
,L_QUANTITY
,L_EXTENDEDPRICE
,L_SHIPDATE
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE to_varchar(L_SHIPDATE,'YYYYMMDD')::INT BETWEEN 19971001 AND 19971031;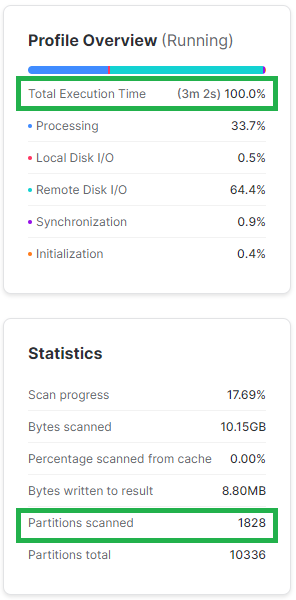
3. Agreguj wcześnie
Jeśli zagregujesz dane przed rozpoczęciem transformacji i łączeń tabel sprawisz, że Snowflake będzie miał znacznie mniej pracy. Łatwo sobie wyobrazić, że złączenie 2 tabel zagregowanych do miliona wierszy jest łatwiejsze niż złączenie 2 tabel składających się z 10 milionów wierszy.
To samo dotyczy transformacji danych.
4. Transformuj późno
Zalety późnej transformacji wynikają z szybkiego filtrowania i wczesnej agregacji tabel. Im mniej wierszy jest w transformowanym zbiorze tym mniej pracy jest do wykonania.
Tu przykład przedstawię na przykładowych danych „S & P 500 by domain and aggregated by tickers (Sample)” dostępnych w Marketplace. Na podstawie dostępnych danych chcę sprawdzić ile wizyt rocznie na swojej stronie osiągały poszczególne spółki. Zbiór danych jest dość mały, więc wyniki nie będą spektakularne, ale wystarczająco duże, żeby zauważyć regułę.
WITH CTE_A AS (
SELECT YEAR(DATE) AS YEAR
,CONCAT(YEAR,'_',COMPANY_NAME,' (',TICKER,'): ',DOMAIN) AS COMPANY
,LEN(COMPANY) AS COMPANY_NAME_LENGTH
,TOTAL_VISITS
FROM SP500.SP500.SP500
)
SELECT COMPANY
,COMPANY_NAME_LENGTH
,YEAR
,SUM(TOTAL_VISITS) AS TOTAL_VISITS
FROM CTE_A
GROUP BY 1,2,3;W mniej optymalnej wersji zapytania widać, że Snowflake najpierw musi policzyć transformacje, żeby zagregować dane.
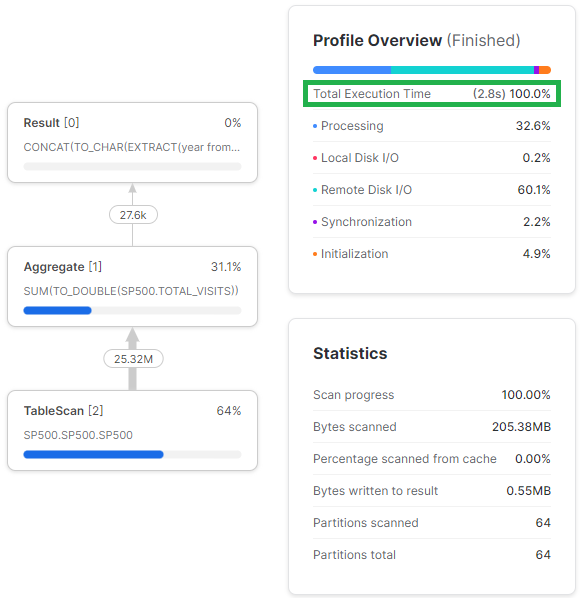
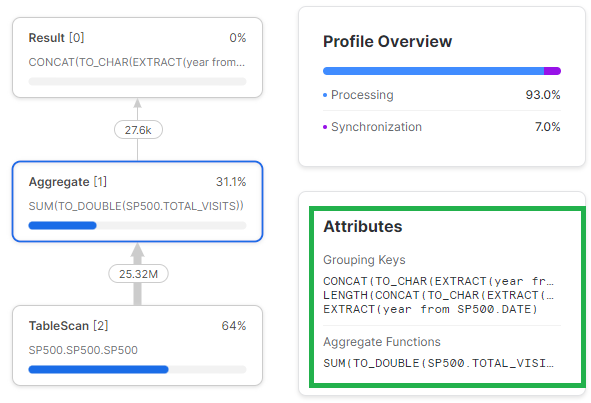
WITH A as
(
SELECT COMPANY_NAME
,TICKER
,DOMAIN
,YEAR(DATE) AS YEAR
,SUM(TOTAL_VISITS) AS TOTAL_VISITS
FROM SP500.SP500.SP500
GROUP BY 1,2,3,4
)
SELECT CONCAT(YEAR,'_',COMPANY_NAME,' (',TICKER,'): ',DOMAIN) AS COMPANY
,LEN(COMPANY) AS COMPANY_NAME_LENGTH
,YEAR
,TOTAL_VISITS
FROM A;W bardziej optymalnej wersji zapytania Snowflake najpierw zagreguje dane i dopiero w ostatnim etapie, na mniejszej liczbie wierszy będzie przeprowadzał transformacje kolumn.
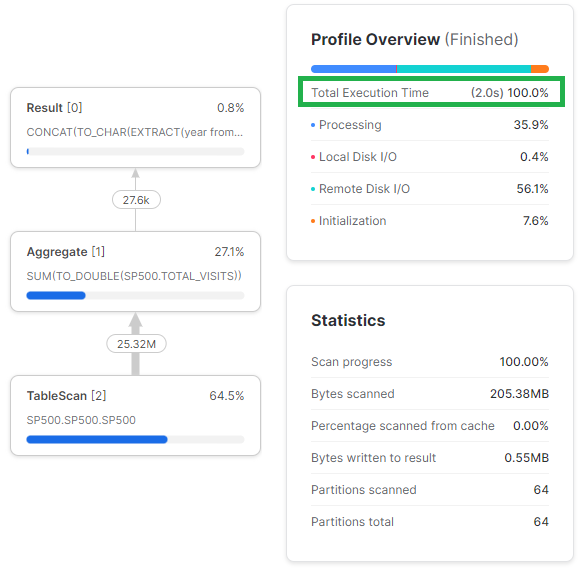
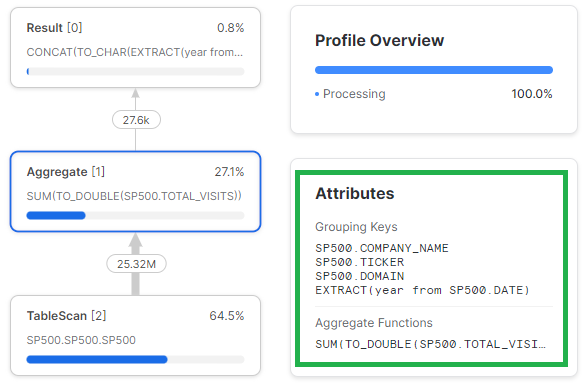
5. Weryfikuj profile zapytań
Optymalizacja SQL nie obyłaby się bez czytania profili zapytań. Snowflake udostępnia wizualnie dość czytelne profile, więc warto do nich zaglądać. Jeśli zapytanie trwa zbyt długo warto tam zajrzeć i zidentyfikować wąskie gardła. Elementy, które warto sprawdzić na samym początku to:
- złączenia kartezjańskie
- w wyniku złączenia Snowflake produkuje więcej wierszy niż się spodziewasz
- rozlewanie danych na dysk
- klaster obliczeniowy nie jest w stanie pomieścić danych w pamięci i zaczyna korzystać z dysku SSD i później bucketów chmurowych (S3 itp.)
- data pruning
- być może filtrujesz tabele po kolumnach, które są słabo sklastrowane i Snoflake musi odczytać znacznie więcej mikro-partycji niż byłoby to optymalne
Podsumowując
Optymalizacja SQL jest bardzo istotnym czynnikiem na szybkość i koszt wykonywania zapytań i Snowflake jako baza danych w chmurze nie zwalnia Cię z odpowiedzialności za pisanie efektywnego kodu.
Jako uzupełnienie przyczyn dlaczego te wskazówki optymalizacji działają wyjaśnia sposób, w jaki Snowflake przechowuje fizycznie tabele.
Na wydajność zapytań wpływa też ilość danych, jakie Snowflake odczytuje z pamięci podręcznej, która jest znacznie szybsza, niż odczytywanie świeżych danych z magazynów chmurowych.
Dodaj komentarz