Architektura Snowflake’a, ale zanim przejdziemy do niej opiszę 3 wcześniejsze podejścia. W końcu, żeby coś bardziej docenić i zrozumieć warto to porównać z alternatywnymi rozwiązaniami.
Architektura Tradycyjna
Tutaj wszystko jest dzielone wspólnie: procesor, RAM, dysk. Problemem tego podejścia jest skalowalność. Możesz rozbudować fizyczny serwer o najmocniejsze procesory, najszybszy dysk, więcej szybkiej pamięci RAM, jednak takie rozwiązanie ma swoje ograniczenia.
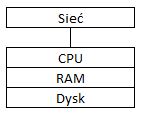
Procesy ETL, ad-hoc’owe zapytania analityczne i zapytania prosto z narzędzi Business Intelligence walczą o te same zasoby, więc w przypadku zbyt wielu ciężkich zapytań można łatwo zawiesić cały system.
Kolejnym minusem są koszty, które trzeba ponieść, żeby rozpocząć pracę z taką maszyną, a później ją utrzymać. Trzeba również przewidzieć jak bardzo system będzie się rozrastać. W przypadku niedoszacowania wymagań względem sprzętu będą konieczne dodatkowe koszty. W sytuacji przeszacowania wymagań organizacja poniesie znacznie większe koszty niż było to konieczne.
Architektura Dzielenia Dysku
Żeby pozbyć się ograniczeń tradycyjnej architektury można podejść do tematu od strony wspólnego dysku z danymi i różnych maszyn obliczeniowych. Maszyny w takiej architekturze mogą być przeznaczone do różnych celów, np.:
- jedna dla narzędzi BI i zapytań ad-hoc
- druga do procesów ETL.
I pięknie, ale…
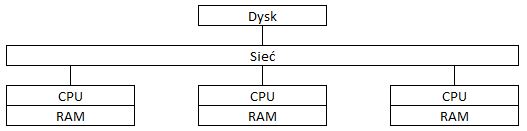
Takie podejście cierpi na ograniczenie związane z dostępnością do dysku:
- ograniczenia sieci
- blokowanie rekordów przy zapisie i odczycie (zależnie od ustawień bazy)
- ograniczenia przepustowości odczytu i zapisu dysku
Architektura Dzielenia Niczego
W tym przypadku dysk już nie jest dzielony między klastry, ale każdy klaster obliczeniowy ma przypisany własny dysk. Każdy z klastrów może być odpowiednio zeskalowany do nakładów pracy, jakie ma realizować.
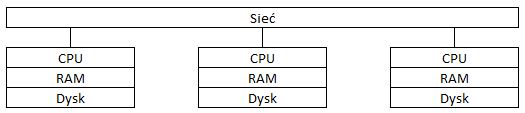
W tym przypadku wąskim gardłem jest przepustowość sieci, gdyż ta architektura wymaga transferu danych, by dzielić się informacjami między shardami (dyskami poszczególnych klastrów). Z założenia tej architektury baza danych jest dzielona na mniejsze części zapisywane na dyskach poszczególnych klastrów. Sprawia to, że utrudnione jest utrzymanie takiej architektury, jak i indywidualne dostrajanie zasobów na potrzeby indywidualnych procesów.
Architektura Snowflake’a
Snowflake jako platforma w tle działa całkowicie w chmurze (do wyboru są: AWS, Microsoft Azure i Google Cloud). Warto zauważyć, że poza różnorodnością wyboru tła dla Platformy Danych, zależnie od wybranej chmury i regionu będą się też różnić ceny za przechowywanie danych i ich przetwarzanie.
Dzięki architekturze zaprojektowanej specyficznie pod kątem wykorzystania możliwości chmury obliczeniowej Snowflake pozbywa się ograniczeń:
- związanych z ograniczeniem dostępu do odczytu i zapisu danych przy większym ruchu
- z dostępem do mocy obliczeniowej, którą można zwiększyć niemal na pstryknięcie palcem
(tutaj oczywiście limitem jest głębokość kieszeni i zdrowy rozsądek)
Snowflake rozwiązuje problemy i ograniczenia powyższych rozwiązań dzięki architekturze trójwarstwowej:
- Usługi chmurowe (Cloud services)
- Przetwarzanie zapytań (Query processing)
- Przechowywanie baz danych (Database storage)
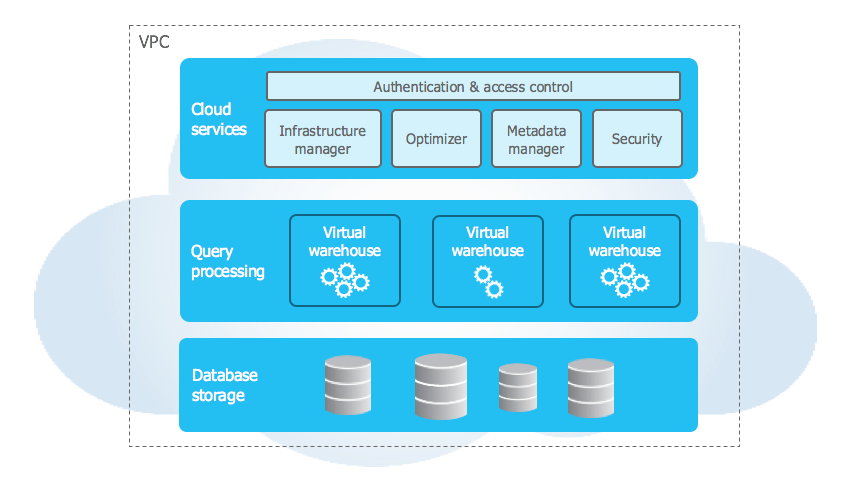
Usługi Chmurowe
Warstwa zarządzająca wszystkim, co dzieje się pod maską Snowflake’a. Koordynuje aktywności, jakie zachodzą na platformie. Odpowiada za kwestie autentykacji, zarządzania infrastrukturą, zarządzania metadanymi, przetwarzaniem zapytań i ich optymalizacją, kontrolą dostępów i optymalizacją obiektów w tle (użytkownik nie ma wpływu na to w jaki sposób są tabele partycjonowane – Snowflake sam zarządza tym procesem i automatycznie re-partycjonuje obiekty w tle).
Przetwarzanie zapytań
Warstwa obliczeniowa składająca się z wirtualnych magazynów (kiepskie tłumaczenie z Virtual Warehouse). Każdy virtual warehouse składa się z wirtualnie przydzielonego procesora i pamięci, który można dowolnie skalować od rozmiarów XS do 6XL. Każdy rozmiar wyżej jest 2 razy mocniejszy niż poprzedni, ale też jego używanie kosztuje 2 razy więcej.
Dzięki możliwości utworzenia wielu klastrów wirtualnych magazynów można dowolnie dostosować ich ilość i rozmiary do potrzeb organizacji, różnych działów i różnych procesów.
Warto wspomnieć, że tutaj też obowiązuje zasada pay-as-you-go. Każdy z warehouse’ów można włączać i wyłączać, a najmniejsza jednostka czasu, za którą się płaci to minuta. Koszt pracy 1 magazynu w rozmiarze XS to 1 kredyt, a koszt kredytu zależy od dostawcy chmury i regionu.
Przechowywanie baz danych
Użytkownicy definiują logiczne hierarchie i obiekty w bazach danych, a Snowflake automatycznie optymalizuje je, kompresuje i zapisuje we własnym formacie kolumnowym. Nikt nie ma bezpośredniego dostępu do plików, które składają się na zapisane obiekty – dostęp jest wyłącznie poprzez zapytania SQL po zalogowaniu się na swoje konto. Użytkownicy nie mają też wpływu jak tabele będą optymalizowane, ani które dane znajdują się w których mikro-partycjach tabel – jest to część samodzielnie zarządzanej platformy danych, którą szczyci się Snowflake.
Dodaj komentarz