
Różne cele do zrealizowania i ich cena.
Korzystanie z rozwiązań chmurowych generują koszty… i warto nad nimi panować dobierając odpowiednie narzędzia do wyznaczonego celu.
Snowflake udostępnia dużo rodzajów tabel zależnie od Twoich potrzeb. Do wybrania odpowiedniego rodzaju tabeli przydadzą się odpowiedzi na pytania:
- czy potrzebujesz korzystać z dodatkowych rozwiązań jak Time Travel?
- czy potrzebujesz materializować tabele na stałe czy są potrzebne jedynie na chwilę?
- czy muszą być przechowywane i w pełni zarządzane wewnątrz architektury Snowflake’a?
- jaki jest w ogóle charakter danych, jakie ma tabela przechowywać?
Z tego wpisu dowiesz się:
- Jakie są 3 podstawowe rodzaje tabel w Snowflake’u.
- Jak wykorzystać definicje baz danych i schematów oraz dziedziczenie ich domyślnych parametrów w celu zarządzania tabelami.
- Poznasz pozostałe 6 rodzajów tabel, którymi zoptymalizujesz wykorzystanie Snowflake’a na swoje potrzeby.
Zajrzyj też do zapoznania się z wpisem o tym jak bazy kolumnowe przechowują tabele. Stanowi on dobre uzupełnienie wiedzy o tabelach w Snowflake’u.
3 podstawowe tabele
Stałe / Permanentne Tabele
CREATE TABLE table_name ...Domyślnym rodzajem tabeli w Snowflake’u jest tabela permanentna. Nazwa „tabela permanentna” może być odrobinę myląca ze względu na fakt, że wszystkie fizyczne tabele poza tymczasowymi pozostają obecne w bazie danych póki nie zostaną jednoznacznie usunięte.
Wbudowanymi cechami tabel stałych są:
- Fail-safe
Funkcja zarządzana przez Snowflake – użytkownicy nie mają wglądu ani możliwości jej edycji. Obejmuje ona dane z ostatnich 7 dni. Przydatna w sytuacjach kryzysowych (awaria systemu, naruszenia bezpieczeństwa danych). By z niej skorzystać użytkownik musi skontaktować się bezpośrednio ze wsparciem Snowflake’a. - Time Travel
Funkcja zarządzana przez użytkowników – umożliwia odpytywanie danych z konkretnego momentu w przeszłości aż do 90 dni wstecz. Domyślny zakres podróży w czasie to 1 dzień. Administrator może zmienić domyślne wartości na poziomie bazy danych i schematów. Może też ustawić je indywidualnie na indywidualnych tabelach. Należy jednak mieć na uwadze 2 fakty:- żeby wykorzystać Time Travel dłuższe niż 24 godziny trzeba korzystać z licencji Snowflake Enterprise Edition lub wyższej
- wszystkie przechowywane zmiany z przeszłości zajmują przestrzeń dyskową, za którą również pobierane są opłaty.
Stałe tabele zalecane są do danych krytycznych dla biznesu, które są trudne lub wręcz niemożliwe do odzyskania w przypadku awarii lub przypadkowego ich usunięcia.
Tabele Transient (Transient Table)
CREATE TRANSIENT TABLE table_name ...Są tańszą wersją tabel permanentnych. Nie są wyposażone w usługę Fail-safe, a podróże w czasie mają ograniczone do maksymalnie 1 dnia (niezależnie od licencji Snowflake’a).
Są dobrym wyborem dla środowisk developerskich lub jako tabele przejściowe.
Tymczasowe (Temporary Table)
CREATE TEMPORARY TABLE table_name ...Tymczasowe tabele istnieją tylko w czasie trwania pojedynczej sesji. Pojedyncza sesja obejmuje pojedynczy arkusz w czasie tego samego zalogowania się do Snowflake’a. Sesja kończy się w momencie wylogowania się, zamknięcia arkusza lub utraty połączenia. Z końcem sesji utworzone tabele tymczasowe są permanentnie usuwane.
Ze względu na swoją ograniczoną czasowo egzystencję tabele tymczasowe nadają się świetnie jako:
- tabele przejściowe podczas przetwarzania danych w pojedynczej sesji
- tabele testowe podczas przeprowadzania testów i analizy danych.
Utworzenie tabeli tymczasowej wymaga przypisanie jej do konkretnej bazy danych i schematu. Nazwa tabeli tymczasowej nie musi być unikatowa względem tabel trwałych – w sytuacji tej samej nazwy z tabelą trwałą, na czas sesji trwała tabela przestaje być widoczna z poziomu kodu SQL i wszelkie zapytania są kierowane do tabeli tymczasowej.
Przerywnik o bazach, schematach i dziedziczeniu
Jak zapewne już wiesz, tabela, jak prawie wszystkie obiekty w Snowflake’u, musi znajdować się w schemacie, a schemat w bazie danych.
CREATE DATABASE baza_danych;
CREATE SCHEMA baza_danych.nazwa_schematu;
CREATE TRANSIENT SCHEMA baza_danych.transient_schema;
ALTER DATABASE baza_danych
SET DATA_RETENTION_TIME_IN_DAYS = 90;No i to by było prawie wszystko.
Bazy danych i schematy też mogą być Transient.
CREATE TRANSIENT DATABASE baza_danych_transient;
CREATE TRANSIENT SCHEMA nazwa_schematu_transient;
CREATE SCHEMA nazwa_schematu_domyslnego;Poniżej zauważysz, że zgodnie z powyższym kodem baza_danych jest permanentna z możliwością podróży w czasie do 90 dni, a baza transient pozostała z domyślnym 1 dniem time travel.
SELECT database_name
,is_transient
,retention_time
FROM SNOWFLAKE.INFORMATION_SCHEMA.DATABASES
WHERE DATABASE_NAME ILIKE 'baza%';
Teraz szczegóły schematów z permanentnej bazy danych.
SELECT catalog_name
,schema_name
,is_transient
,retention_time
FROM BAZA_DANYCH.INFORMATION_SCHEMA.SCHEMATA;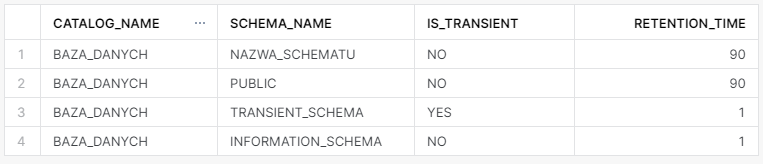
I jeszcze informacje o schematach z bazy stworzonej jako transient.
SELECT catalog_name
,schema_name
,is_transient
,retention_time
FROM BAZA_DANYCH.INFORMATION_SCHEMA.SCHEMATA;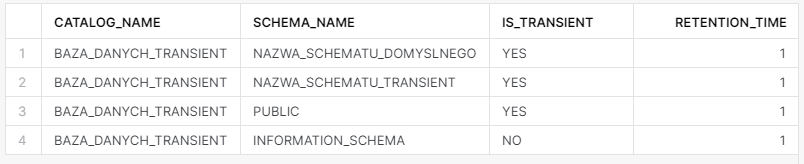
Z powyższych przykładów można wyciągnąć kilka wniosków:
- Domyślnie wszystkie obiekty są permanentne.
- Żeby utworzyć obiekt transient musisz go zdefiniować jako transient
np.CREATE TRANSIENT DATABASE baza_transient;. - Obiekty dziedziczą typ od obiektu wyżej, więc domyślnie tabela utworzona w schemacie transient również będzie transient.
- Typ obiektu nadrzędnego ustala też najwyższy typ obiektu podrzędnego, więc w schemacie transient nie utworzysz permanentnej tabeli.
| Funkcjonalność | Permanent | Transient |
|---|---|---|
| Time Travel | 0-90 dni | 0-1 dni |
| Fail Safe | 7 dni | brak |
Więcej o podróżach w czasie i Fail Safe będzie w innym wpisie, a tymczasem przejdę w końcu do pozostałych tabel, jakie możesz stworzyć.
Pozostałe 6 tabel
Tworząc te tabele nie możesz w ich definicji zdecydować, czy będą transient lub permanent. Niektóre z tych tabel dziedziczą te parametry zgodnie z definicją schematu, a dla pozostałych jest to całkowicie obojętne, gdyż nie są w stanie skorzystać z podróży w czasie czy Fail Safe.
Tabele Dynamiczne (Dynamic Table)
CREATE DYNAMIC TABLE table_name
TARGET_LAG = 'częstotliwość odświeżania tabeli'
WAREHOUSE = wybrany_warehouse
AS
SELECT ...Jedna z ciekawszych tabel dostępnych w Snowflake’u – póki co w Public Preview (stan na 2024-02-18). Dokumentacja: link.
Świetne rozwiązanie w celu zautomatyzowania przetwarzania danych wewnątrz Snowflake’a. Są zmaterializowanymi tabelami, które odświeżają się zgodnie z ustaloną częstotliwością. Najmniejszy przedział czasu do odświeżenia to 1 minuta. Należy zaznaczyć, że jest to częstotliwość „mniej więcej” – Snowflake nie gwarantuje, że uruchomi odświeżenie tabeli w dokładnie tej częstotliwości.
Domyślnie tabela dynamiczna jest odświeżana inkrementalnie aktualizując jedynie wiersze na podstawie danych, które zmieniły się w tabelach źródłowych. W sytuacjach gdy Snowflake nie jest w stanie automatycznie ustalić które wiersze należy zaktualizować przeprowadza pełne odświeżenie. Moment uruchomienia odświeżania tabeli nadzorowany jest przez element architektury Snowflake’a usług chmurowych, które działają zawsze w tle. (więcej o architekturze Snowflake’a tutaj)
Koszty ponoszone na tabele dynamiczne to oczywiście koszt przechowywania i przetwarzania danych.
Najlepiej sprawdzą się przy automatyzowaniu przepływów ETL bez potrzeby wykorzystania zewnętrznych narzędzi (Snowflake wizualizuje zależności między tabelami w czytelnych DAG’ach).
Tabele Hybrydowe (Hybrid Table)
(nareszcie dostępne w public preview!)
CREATE HYBRID TABLE tabel_hybrydowa (
id NUMBER PRIMARY KEY AUTOINCREMENT START 1 INCREMENT 1,
kolumna_1 VARCHAR NOT NULL,
kolumna_2 VARCHAR NOT NULL
);Snowflake już dawno temu ogłosił prace nad tymi tabelami, aż w końcu w lutym 2024 udostępnił je do Public Preview. Na dzień pisania tego wpisu są dostępne jednak jedynie w 3 regionach Snowflake’a postawionego na AWS. Dla darmowych kont trial również nie są one jeszcze dostępne.
Tabele Hybrydowe jednocześnie korzystają z zalet przechowywania kolumnowego jak również podlegają standardom tabel wierszowych. Zapisywane dane są najpierw w formacie wierszowym, a później asynchronicznie kopiowane do formatu kolumnowego. Umożliwiają tworzenie indeksów, a wszystkie ograniczenia (constrainty) są egzekwowane.
Wykorzystując tabele hybrydowe jesteś w stanie zbudować aplikację transakcyjną w oparciu o nie właśnie, a w razie potrzeby ich przeanalizowania nie masz już potrzeby transferu tych danych do analitycznej bazy danych – wszystko możesz zrealizować wewnątrz Snowflake’a.
Wadą tabel hybrydowych jest z kolei znacznie większe wykorzystanie przestrzeni dyskowej, jak również zwiększone wykorzystanie obliczeń serverless na synchronizację danych do formatu kolumnowego.
Tabele Zdarzeń (Event Table)
CREATE EVENT TABLE baza_danych.schemat.zdarzenia;
ALTER ACCOUNT SET EVENT_TABLE = baza_danych.schemat.zdarzenia;Tabele zdarzeń są specjalnym typem tabel zaprojektowanym do zbierania logów i zdarzeń z wykonywanych procedur składowanych i zdefiniowanych funkcji użytkownika.
Żeby tabela zbierała logi poza stworzeniem musisz ją aktywować, przypisać do konta, oraz zdefiniować procedury i funkcje w taki sposób, żeby emitowały logi. Dokładny opis i szczegółową instrukcję do tabel zdarzeń znajdziesz w dokumentacji Snowflake’a.
Do tabeli zdarzeń nie zapiszesz danych ręcznie poleceniem INSERT. Możesz jednak usunąć z niej wszystkie rekordy wykorzystując TRUNCATE lub pojedyncze wiersze przez DELETE.
Tabele zdarzeń z powodzeniem możesz wykorzystać do śledzenia wykorzystania i wydajności procedur składowanych i funkcji.
Tabele Zewnętrzne (External Table)
-- stworzenie definicji formatu pliku
CREATE FILE FORMAT PARQ
TYPE = PARQUET
COMPRESSION = SNAPPY;
-- stworzenie Stage z adresem do plików z danymi tabeli
CREATE STAGE s3_fact_crimes
STORAGE_INTEGRATION = s3_int
URL = 's3://project_name/fact_crimes.parquet/'
FILE_FORMAT = PARQ;
-- stworzenie tabeli zewnętrznej
CREATE EXTERNAL TABLE crimes
WITH LOCATION = @s3_fact_crimes
FILE_FORMAT = (FORMAT_NAME = PARQ);Jak sama nazwa wskazuje, zewnętrzne tabele są przechowywane poza granicami Snowflake’a -> Amazon S3, Google Cloud Storage, Microsoft Azure. Po utworzeniu takiej tabeli Snowflake przechowuje niektóre metadane dotyczące plików znajdujących się w stage’u.
Ze względu na to, że Snowflake nie zarządza przechowywaniem tych danych, możesz jedynie odczytywać dane z tabel zewnętrznych.
Wydajność odczytu tych tabel może być słabsza od tych w pełni zarządzanych przez Snowflake, jak również koszty ich przetwarzania mogą być większe. Dodatkowo dochodzą też koszty odświeżania metadanych o tabelach zewnętrznych, jak również potencjalne koszty transferu danych, jeśli są one w innym regionie/chmurze niż Twoje konto Snowflake.
Tabele zewnętrzne standardowo mają zaledwie 3 kolumny:
| Kolumna | Opis |
|---|---|
| value | kolumna typu variant reprezentująca pojedynczy wiersz z zewnętrznej tabeli |
| metadata$filename | zawiera nazwę pliku i jego ścieżkę, w którym dany wiersz jest przechowywany |
| metadata$file_row_number | reprezentuje numer wiersza w pliku tabeli zewnętrznej |
W celu ułatwienia korzystania z zewnętrznych kolumn możesz wykorzystać kolumny wirtualne, o których już napisałem wcześniej.
Tabele zewnętrzne przydadzą się, jeśli z jakiegokolwiek powodu nie chcesz fizycznie przechowywać tych informacji fizycznie w Snowflake’u, lub jeśli chcesz pozostawić zarządzanie tabelą osobom zewnętrznym, które nie powinny mieć bezpośredniego dostępu do Twojego konta.
Niewątpliwymi wadami tego rozwiązania są jednak kwestie związane z wydajnością i potrzebą dodatkowej pracy przy aktualizacji metadanych. Istotną kwestią do wzięcia pod uwagę jest też kwestia kompletności danych – jeśli Snowflake napotka jakiś błąd w którymś z odczytywanych plików, to go pominie i wyświetli dane wszystkich pozostałych, co będzie skutkować w braku kompletu danych.
Tabele Katalogów (Directory Table)
Przechowują metadane o plikach znajdujących się w Stage’u. Możliwość jej utworzenia masz przy tworzeniu nowego Stage’a lub za pomocą komendy ALTER na już istniejącym.
--przy tworzeniu stage'a
CREATE STAGE nazwa_stagea
STORAGE_INTEGRATION = s3_integration
URL = 's3://nazwa_bucketa'
DIRECTORY = (ENABLE = TRUE); --> polecenie do utworzenia tabeli
--lub przy pomocy komendy ALTER
ALTER STAGE nazwa_stagea SET DIRECTORY (ENABLE = TRUE);Odczytywanie danych z takich tabel jest dość nietypowe – wymaga zastosowania funkcji DIRECTORY() na odwołaniu do stage’a.
SELECT * FROM DIRECTORY(@nazwa_stagea);
Tabele Katalogów przydadzą się do przeszukiwania Stage’a pod kątem znajdujących się tam plików, lub tworzenia baz metadanych przetwarzanych plików.
Iceberg
Kolejny nowy rodzaj tabeli, który na ten moment jest jeszcze w Public Preview. Iceberg są oparte na formacie tabel Apache Iceberg.
Dane tych tabel znajdują się w zewnętrznych bucketach chmur, a możesz odpytywać je zupełnie tak samo, jak te przechowywane wewnątrz Snowflake’a. Są idelnym rozwiązaniem w sytuacji, gdy nie chcesz, lub nie możesz zapisać danych natywnie w Snowflake’u. Obecnie jedynym formatem plików, jakie Snowflake jest w stanie odczytać przy wykorzystaniu tabel Iceberg jest Apache Parquet.
Żeby stworzyć taką tabelę musisz ustanowić integrację z bucketem oraz EXTERNAL VOLUME. Bucket musi się też znajdować w tym samym regionie tej samej chmury, co Twoje konto Snowflake, w przeciwnym razie otrzymasz błąd przy tworzeniu tabeli.
Możesz zarówno stworzyć pustą tabelę i wykonując operacje DML Snowflake będzie zarządzał plikami Parquet.
CREATE OR REPLACE ICEBERG TABLE customer_iceberg (
c_custkey INTEGER,
c_name STRING,
c_address STRING,
c_nationkey INTEGER,
c_phone STRING,
c_acctbal INTEGER,
c_mktsegment STRING,
c_comment STRING
)
CATALOG='SNOWFLAKE'
EXTERNAL_VOLUME='iceberg_lab_vol'
BASE_LOCATION='';
INSERT INTO customer_iceberg
SELECT * FROM snowflake_sample_data.tpch_sf1.customer;
SELECT TABLE_NAME
,TABLE_TYPE
,IS_TRANSIENT
,RETENTION_TIME
,IS_INSERTABLE_INTO
,IS_ICEBERG
FROM ICEBERG_LAB.INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'ICEBERG_LAB';
Ten typ tabel umożliwia Time Travel, ale nie wspiera Fail Safe.
Dodaj komentarz