Co to jest widok zmaterializowany?
Widok zmaterializowany to nic innego, jak wstępnie przeliczony zestaw danych na podstawie definicji zapisanej w widoku. Snowflake przechowuje widoki zmaterializowane tak samo jak tabele.
Definicja tworzenia widoku zmaterializowanego jest dość prosta:
CREATE MATERIALIZED VIEW AS <...>Żeby z nich skorzystać musisz mieć przynajmniej edycję Enterprise Snowflake’a.
Zalety widoków zmaterializowanych
- Mogą znacznie przyspieszyć realizację zapytań, które są skomplikowane i często uruchamiane
- Utrzymywane/aktualizowane automatycznie za każdym razem, gdy tabela bazowa zostanie zmieniona
- Niezależnie, czy widok zmaterializowany został zaktualizowany do ostatnich zmian w tabeli bazowej czy nie i tak zapytania do widoku zmaterializowanego odwzwierciedlą najnowszy stan tabeli bazowej – Snowflake odczyta zmiany/brakujące wiersze z tabeli bazowej
- Zapytania skierowane do tabeli bazowej, jeśli optymalniej będzie je wykonać na widoku zmaterializowanym, zostaną automatycznie w tle przekierowane do widoku (zmiana będzie widoczna w profilu zapytania)
Wady widoków zmaterializowanych
- Mogą okazać się bardzo kosztowne w utrzymaniu (koszt aktualizacji + koszt przechowywania wraz z time-travel i fail-safe)
- Widok zmaterializowany może być zbudowany wyłącznie w oparciu o pojedynczą tabelę – joiny nie są wspierane
- Nie można wykorzystać wielu funkcji w widokach zmaterializowanych:
- Funkcji okna
- klauzuli HAVING
- ORDER BY
- GROUPING SETS / ROLLUP / CUBE
- MINUS / EXCEPT / INTERSECT
- zapytań zagnieżdżonych
Kiedy rozpatrzeć wykorzystanie widoku zmaterializowanego?
Zgodnie z zaleceniami bezpośrednio od Snowflake’a rozpoczęcie testów z widokami zmaterializowanymi ma sens, gdy wszystkie poniższe kryteria są spełnione:
- Zmiany w tabeli bazowej dla widoku zachodzą rzadko, lub przynajmniej podzbiór danych wykorzystanych dla widoku jest relatywnie niezmienny.
- Dane zapisane w widoku są wykorzystywane często.
- Koszt odtworzenia zapytania jest relatywnie wysoki.
i żadne z poniższych:
- Wyniki widoku zmieniają się często (tabela bazowa jest często aktualizowana).
- Wyniki widoku są odczytywane rzadko.
- Zapytanie tworzące widok jest relatywnie tanie/szybkie.
Ile kosztują widoki zmaterializowane?
Utrzymanie widoków zmaterializowanych jest jedną z droższych usług bezserwerowych w Snowflake’u. Nie ma dostępnych kalkulatorów do ich obliczania, jednak jedynymi składowymi, jakie wchodzą w ich ostateczne koszty są aktualizacje widoków i ich przechowywanie wraz z time-travel i fail-safe.
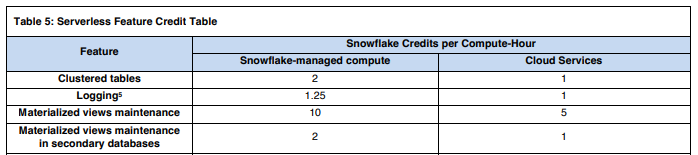
W cenniku Snowflake’a, która jest udostępniona tutaj, widać, że koszty przeliczenia widoków zmaterializowanych są dość znaczne.
- 10 kredytów za godzinę przetwarzania/aktualizacji widoku
- 5 kredytów za obliczenia chmurowe w tle, które Snowflake przeprowadza w celu chociażby reklasteryzacji tych widoków
Dodatkowym kosztem jest też utrzymanie widoków zmaterializowanych w replikach baz danych, które mają w swojej strukturze widoki zmaterializowane, chociaż ich koszt jest znacznie mniejszy.
Najlepsze praktyki według dokumentacji Snowflake
Tworzenie widoków zmaterializowanych – najlepsze praktyki
- Widoki zmaterializowane powinny służyć przynajmniej jednej, a najlepiej obu celom:
- Filtrowanie wierszy i kolumn z tabeli bazowej –
- Obliczanie skomplikowanych transformacji
- Widoki zmaterializowane mogę być wykorzystane do przechowywania danych odstających z tabeli bazowej
- Jednak w takiej sytuacji wartości odstające powinny być łatwe w odseparowaniu od pozostałych informacji, oraz
- tabela bazowa nie jest klastrowana, lub klucz klastra nie obejmuje kolumn identyfikujących dane odstające
- dane odstające są często wykorzystywane.
Utrzymania widoków zmaterializowanych – najlepsze praktyki
Widoki zmaterializowane są drogie w utrzymaniu. Aktualizują się za każdym razem, gdy zajdzie zmiana w tabeli bazowej (dodanie, usunięcie, zmiana wierszy lub reklasteryzacja). W związku z tym najlepszym rozwiązaniem, w celu uniknięcia kosztów częstej aktualizacji, jest jak najrzadsze przeprowadzanie operacji INSERT, UPDATE, DELETE, MERGE i przeprowadzanie ich w większych partiach.
Najlepsze praktyki odnośnie klastrowania widoków zmaterializowanych i tabel bazowych
- Rozważ usunięcie kluczy klastrujących, jeśli tabela bazowa nie jest sama w sobie często odczytywana. Mogą one zwiększyć koszty utrzymania widoku zmaterializowanego. Za każdym razem, gdy tabela bazowa jest reklastrowana, to zachodzi w niej zmiana, do której widok zmaterializowany się dostosowuje.
- Nie klastruj widoków zmaterializowanych, jeśli nie potrzebujesz. Poza dostosowaniem się do zmian w tabeli bazowej ponowna reklasteryzacja widoku zmaterializowanego to dodatkowy koszt.
Przykład
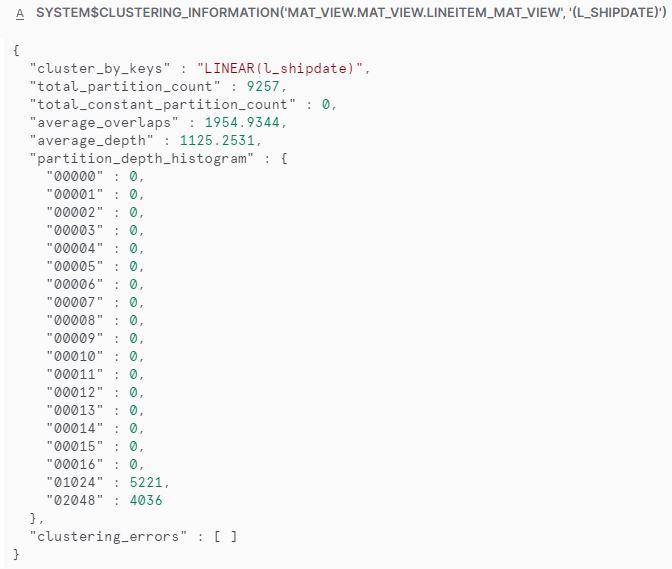
Weźmy tabelę dostępną wśród przykładowych danych dostępnych przy tworzeniu konta w Snowflake: SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM zawierającą blisko 6 miliardów wierszy. Tabela jest posortowana po kolumnie L_SHIPDATE, co można sprawdzić wykorzystując polecenie
SELECT SYSTEM$CLUSTERING_INFORMATION('SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM', '(L_SHIPDATE)');
Przez co wiadomo, że ta kolumna jest dobrze sklastrowana?
- total_constant_partition_count jest niemal tak wysoką liczbą jak liczba wszystkich partycji
- average_overlaps jest niski, co świadczy o niskim poziomie nakładania się wartości między partycjami
- average_depth jest niski, co również świadczy o niskim poziomie nakłądania się danych między partycjami
- partition_depth_histogram przedstawia rozkład nakładających się na siebie mikro-partycji. W tym przykładzie większość mikro-partycji jest zgrupowana przy mniejszych wartościach. To świadczy o dobrym rozkładzie danych i dobrym poziomie klasteryzacji danych w tej kolumnie.
Przykład źle sklastrowanej kolumny

Sprawdzając te same informacje o kolumnie L_COMMITDATE zobaczymy zupełnie przeciwny obrazek.
- brak stałych mikro-partycji
- wysoka liczba nakładających się danych
- wysoka głębokość nakładających się danych
- histogram przesunięty w kierunku maksymalnych wartości
To wszystko świadczy o tym, że ta kolumna nie nadaje się do filtrowania i wyszukując po dacie deklaracji najprawdopodobniej Snowflake i tak będzie musiał odczytać dużą liczbę partycji w celu zwrócenia danych.
Załóżmy, że do tej tabeli są jedynie zapisywane nowe wiersze zgodnie z datą wysłania zamówień, ale biznes chce często odczytywać te dane po kolumnie l_commitdate, czyli dacie deklaracji, na dodatek potrzebują jedynie informacji o tych zamówieniach, które były zadeklarowane od 1 stycznie 1994.
Stwórzmy nowy widok zmaterializowany
Stwórzmy widok zmaterializowany z kluczem klastrującym na kolumnie L_COMMITDATE i sprawdźmy poziom klasteryzacji obu kolumn w widoku zmaterializowanym.
*wcześniej stworzyłem kopię tabeli przykładowej LINEITEMS w mojej bazie danych, bo Snowflake nie umożliwia tworzenia widoków zmaterializowanych na dzielonych bazach danych.
#stworzenie kopii tabeli posortowanej dla pewności po L_SHIPDATE
create table mat_view.mat_view.lineitem
as select *
from snowflake_sample_data.tpch_sf1000.lineitem
order by l_shipdate;#stworzenie widoku zmaterializowanego z kluczem klastrującym na kolumnie L_COMMITDATE i filtrem na tej samej kolumnie
create or replace materialized view mat_view.mat_view.LINEITEM_mat_view
cluster by (l_commitdate) as
select *
from mat_view.mat_view.lineitem
where l_commitdate >= '1994-01-01';W poniższych screenach widać, że widok jest posortowany po kolumnie L_COMMITDATE, a L_SHIPDATE tym razem ma mocno losowy rozkład.

Jak to wpływa na wyszukiwanie danych w tabeli bazowej a widoku zmaterializowanym? Policzmy w takim razie całkowitą wartość towarów, jaką firma zadeklarowała dostarczyć zagregowaną po dniu deklaracji.
#tabela bazowa
select l_commitdate, sum(l_extendedprice)
from snowflake_sample_data.tpch_sf1000.lineitem
where l_commitdate between '1995-03-01' and '1995-03-31'
group by 1;
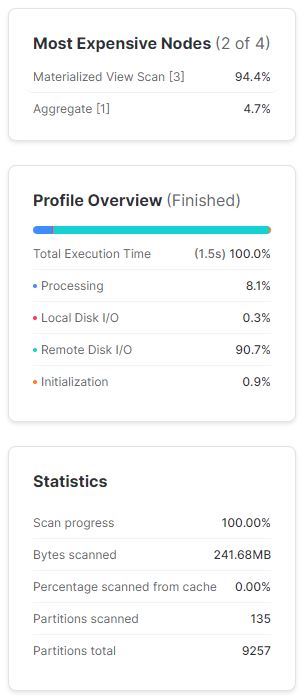
#widok zmaterializowany
select l_commitdate, sum(l_extendedprice)
from mat_view.mat_view.lineitem_mat_view
where l_commitdate between '1995-03-01' and '1995-03-31'
group by 1;Poniższe wyniki dość mocno wskazują na to, jak mocno na szybkość wykonania zapytania wpłynęło posortowanie danych w widoku zmaterializowanym.
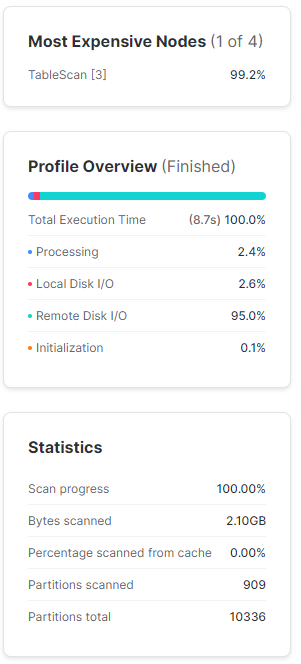
Jak widać odpowiedni widok zmaterializowany może widocznie pomóc w wydajności zapytań. W tym przypadku znacząco zmniejszyliśmy liczbę odczytanych mikro-partycji, co przełożyło się na niemal 6-krotne zwiększenie wydajności przy tym konkretnym zapytaniu.
Zastanawiając się nad stworzeniem widoku zmaterializowanego powinieneś/powinnaś najpierw dokładnie zdefiniować jakiego zysku oczekujesz i później monitorować, czy zysk jest wystarczający, żeby uzasadnić koszty widoku.
Przykładowe koszty widoku zmaterializowanego
W celu monitorowania kosztów można zajrzeć do tabeli snowflake.account_usage.materialized_view_refresh_history. Przykładową zawartość tej tabeli przedstawia poniższy screen.

Dodaj komentarz