Mierzysz się może z którymś z poniższych problemów?
- częste i kosztowne ad-hocowe zapytania łączące wiele tabel
- wielokrotnie zagnieżdżone widoki
- skomplikowane przepływy danych zdefiniowane w graficznych narzędziach ETL
- trudność w utrzymaniu spójności i jakości danych / kodu
- wiecznie nieaktualna lub brak jakiejkolwiek dokumentacji
- długotrwałe i męczące debugowanie kodu i naprawianie błędów zaczynając od identyfikacji ich źródła
dbt może pomóc rozwiązać powyższe problemy. To lekkie open-source’owe narzędzie służące do organizacji i zarządzania Transformacjami danych w procesie ELT. Jest zbudowane wokół Twoich plików .sql lub .py definiujących modele w Twojej bazie danych.
Dostępna jest darmowa wersja core i płatna usługa chmurowa. Wersja core nie ustępuje możliwościami wersji chmurowej, jednak wymaga włożenia większej pracy w architekturę rozwiązania i jej utrzymanie.
W dbt „model” odnosi się do każdego pojedynczego pliku .sql. Każdy model może być materializowany na wiele różnych sposobów:
- tabela
- tabela z wsadem inkrementalnym
- widoki
- ephemerale, które można porównać do modułów CTE
ephemerale nie są materializowane w żaden sposób w bazie, ale każdy inny moduł może się do nich odwołać
Głównym zadaniem dbt jest kompilacja Twoich plików .sql do kodu SQL i uruchomienie ich w Twojej bazie.
Dlaczego dbt musi najpierw skompilować zawartość plików .sql? Ze względu na możliwość wykorzystania makr i funkcji z szablonów Jinja.
Dzięki wykorzystaniu Jinja dbt dokładnie wie w jakiej kolejności uruchomić poszczególne modele, które mogą być uruchamiane równolegle.
Do automatyzacji uruchamiania zadań dbt możesz wykorzystać popularne narzędzia do orkiestracji (Airflow, Dagster) lub zaplanować ich uruchamianie bezpośrednio w GitLabie lub GitHubie. Airflow z Dagsterem jednak nadają się do tego znacznie lepiej.
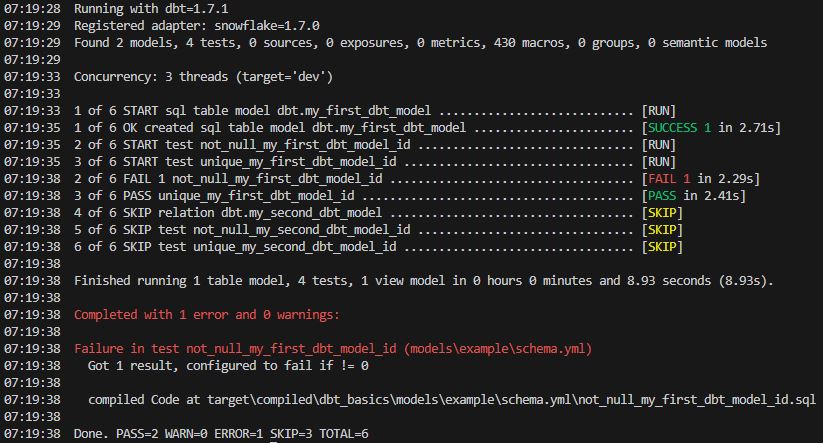
No dobra, ale właściwie w jaki sposób dbt może pomóc w rozwiązaniu wcześniej wymienionych problemów?
Kontrola wersji
Od lat podstawa pracy przy tworzeniu oprogramowania, w pracy analitycznej nadal jest to stosunkowo nowy koncept. Dbt opiera się na pracy z Git’em, co rozwiązuje mnóstwo problemów związanych z wypuszczaniem nowych wersji tabel i widoków:
- ułatwia cofnięcie do poprzedniej wersji w przypadku wykrycia błędów
- ułatwia kontrolę jakości kodu
- ułatwia weryfikację zmian w czasie
- ułatwia zarządzanie kodem w wieloosobowych zespołach
Modułowość
Każdy model jest indywidualnym modułem w całym projekcie dbt. Dbt umożliwia łatwą organizację modeli w schematach bazy danych, a całość jest zarządzana poprzez umieszczenie plików .sql w odpowiednich folderach nadrzędnych. Dzięki umieszczeniu wszystkich modeli w jednym projekcie dbt można bez problemu odwoływać się do już raz stworzonych CTE (modeli ephemeral) lub innych tabel czy widoków.
Drugą stroną modułowości jest też możliwość wykorzystywania wielokrotnie makr. Można je porównać do funkcji zdefiniowanych przez użytkownika, jak również makr już wbudowanych w podstawowe pakiety dbt. Nie tylko umożliwia to zastosowanie tej samej logiki w różnych miejscach kodu w różnych modelach, ale też znacznie ułatwia pisanie skomplikowanego kodu (tutaj dobrym przykładem jest pivot).
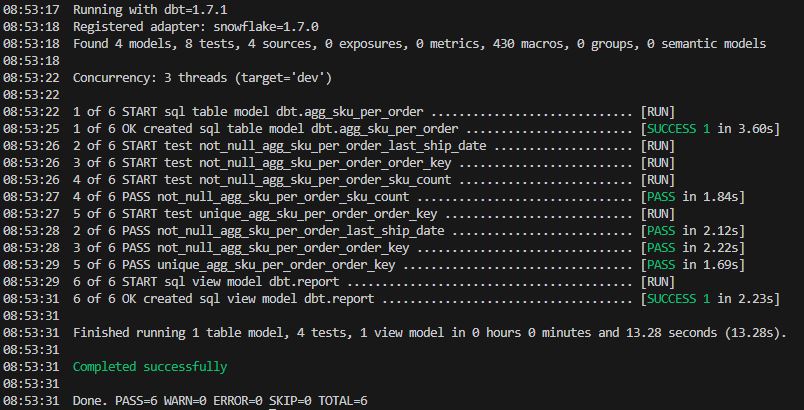
Testy
Dzięki testom możesz łatwo wyłapać potencjalne błędy i anomalie w danych i zareagować zanim końcowi użytkownicy zauważą nieścisłości. W końcu kod może się wykonywać poprawnie nawet, jeśli dane są nieprawidłowe.
Podstawowe testy to:
- unique
- not_null
- relationships
- accepted_values
Jeśli wśród testów zawartych już w dbt nie znajdziesz takiego, którego potrzebujesz, nic nie stoi na przeszkodzie, żeby zdefiniować własne testy.
Otestować możesz nie tylko modele, które tworzysz wewnątrz projektu dbt, ale też tabele źródłowe i seed’y*.
*seed’y to pliki csv, na podstawie których dbt buduje statyczne tabele w bazie danych. Przydatne, gdy zachodzi potrzeba załądowania danych, które nie zmieniają się często i nie są zależne od systemów transakcyjnych firmy.
Przykładem dobrego seed’a będzie lista kodów krajów i ich nazw.
Przykładem kiepskiego seed’a będzie csv z surowymi danymi wyeksportowany z systemu transakcyjnego.
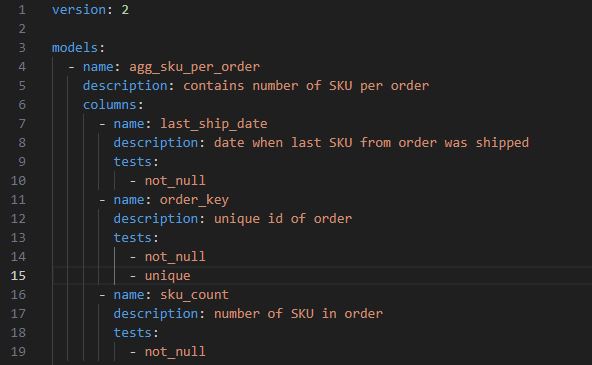
Dokumentacja
Nikt nie lubi pisać dokumentacji. dbt zmniejsza opór przed pisaniem i aktualizowaniem dokumentacji do niespotykanych wcześniej, minimalnych poziomów. Pisanie dokumentacji do modeli wewnątrz projektu dbt staje się po prostu naturalnym procesem nieoderwalnym od pisania samego SQL.
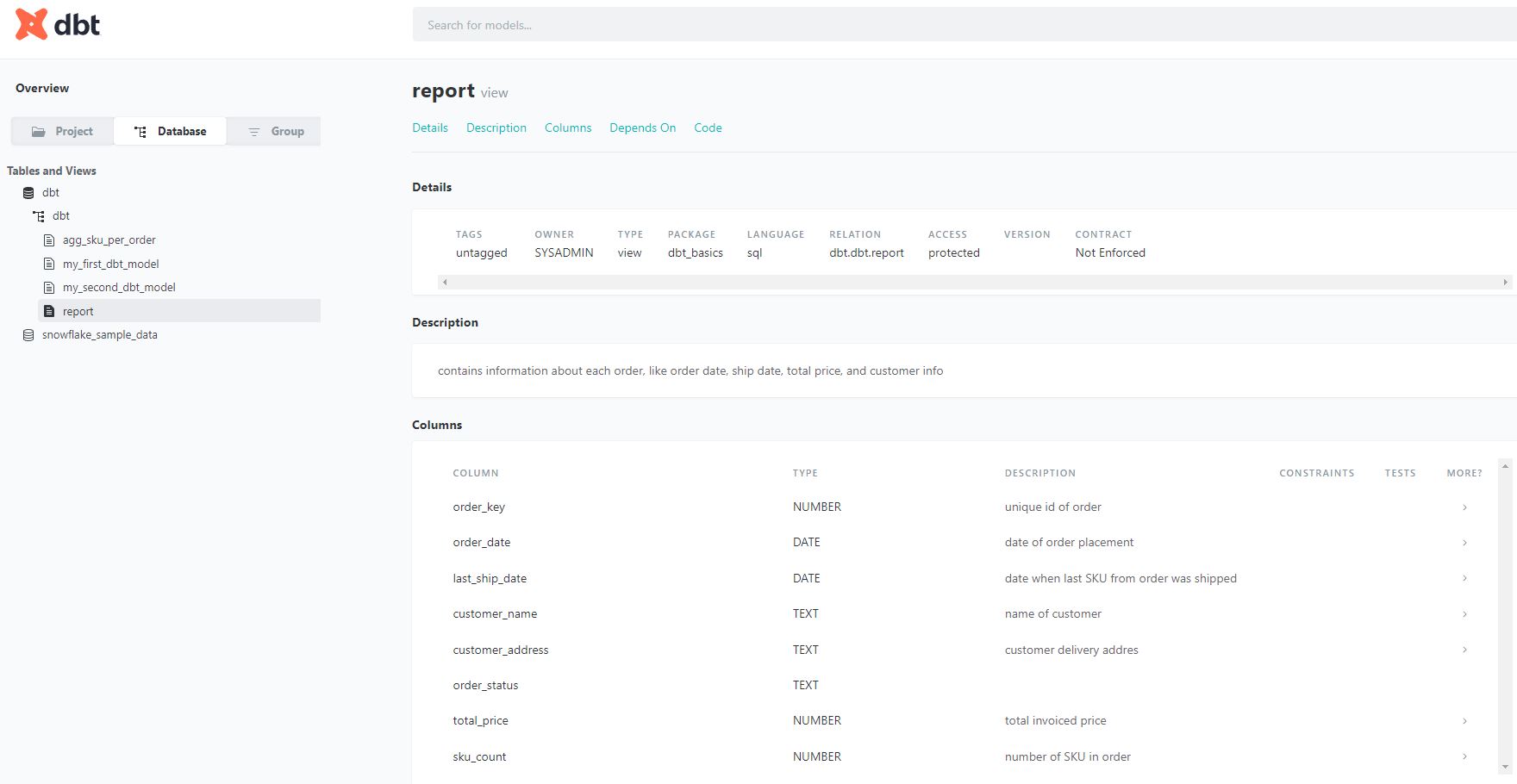
Dokumentacja modeli jest zapisywana w plikach .yml. Umożliwia opisywanie modeli jako całości, każdej kolumny z osobna, a także definiowanie jakie testy należy wykonać na danych modelach i kolumnach.
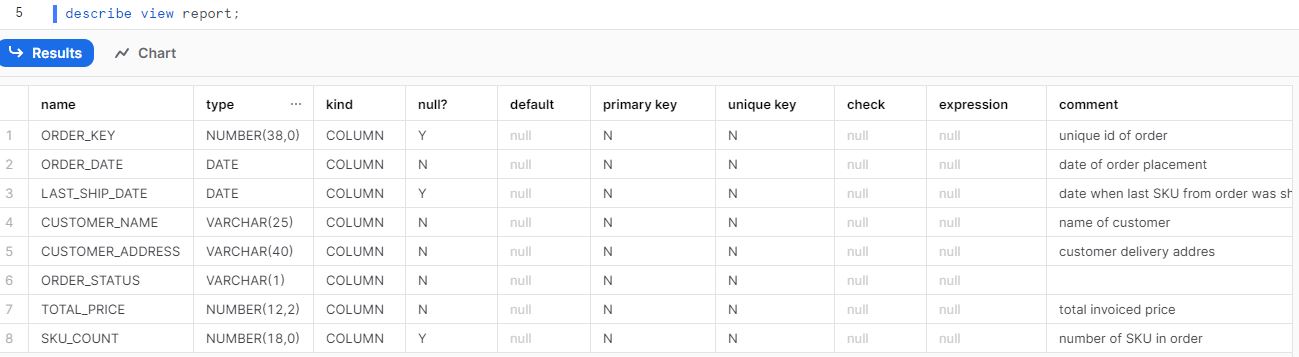
W przypadku Snowflake’a wszystkie opisy mogą być automatycznie zapisywane też w samym SNowflake’u, co znacznie zwiększa czytelność obiektów. Jeśli ktoś korzysta wyłącznie ze Snowflake’a do odczytu danych, lub narzędzi typu Metabase, to jest to idealne rozwiązanie.

Czy dbt jest dla Ciebie i Twojej organizacji?
Przetestuj i sprawdź. Powyżej jedynie drasnąłem temat. dbt łącząc możliwości SQL z Jinja daje naprawdę niesamowite możliwości dostosowywania kodu i przepływów danych do Twoich potrzeb. Korzystanie z niego na Snowflake’u sprawia mi osobiście ogromną frajdę i satysfakcję.
Zachęcam do zajrzenia na stronę projektu dbt.
Dodaj komentarz