Jak bazy kolumnowe przechowują fizycznie dane omówiłem tutaj. W tym wpisie omówię jak manipulacja danymi wpływa na już utworzoną tabelę.
Teoria
Insert a mikro-partycje
Mikro-partycje w Snowflake’u są niemutowalne. Nie można ich edytować w miejscu, a jednak baza umożliwia dodawanie nowych wierszy, ich edycję i usuwanie. Załóżmy, że dodajemy do tabeli z poprzedniego wpisu wiersz z nową transakcją (IDTransakcji = 7). Teoretycznie zapis wiersza odbywa się w nowej partycji – tutaj numer 3. W praktycznej części pokażę, że nie jest to regułą, jeśli zapisujemy do bazy małe bloki danych i dlaczego stanowi to problem. Przy dużej liczbie wierszy zapisywanych za jednym razem nie będzie to stanowić problemu. Nowe partycje będą tworzyć się automatycznie zgodnie z kolejnością zapisywania wierszy.
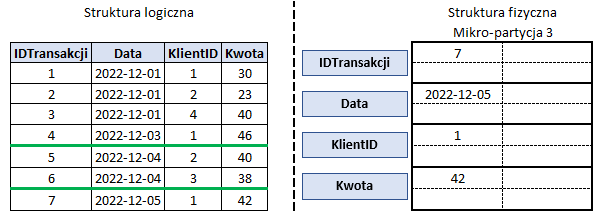
Update & Delete a mikro-partycje
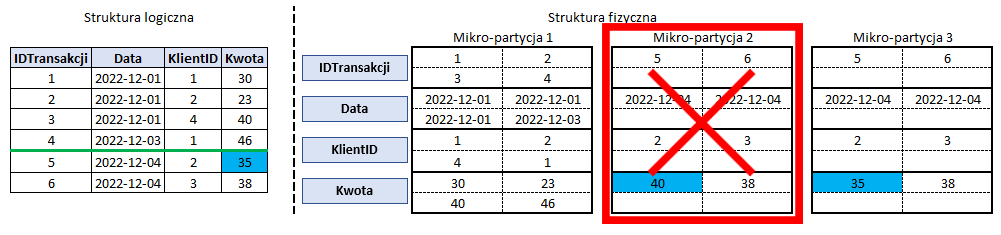
Gdy dokonujemy edycji bądź usunięcia zapisanych już wierszy, Snowflake tworzy nową mikro-partycję z zaktualizowanymi bądź usuniętymi wierszami jednocześnie oznaczając mikro-partycje z nieaktualnymi już wartościami jako nieaktualną. Zależnie od rodzaju tabeli i jej ustawień Snowflake usuwa nieaktualne partycje lub przechowuje je aż do 90 dni.
Poniżej przykład aktualizacji kwoty dla transakcji 5.
Praktyka
Tę część omówię korzystając z lokalnej kopii tabeli SP_500 ze zbioru „S & P 500 by domain and aggregated by tickers (Sample)”. Zbiór jest dostępny za darmo w Snowflake Marketplace. Tabela przed wszelkimi zmianami podzielona jest na 16 partycji.
Insert a mikro-partycje
Dodawanie pojedynczych wierszy
Na początek do tabeli dodam 1 wiersz.
INSERT INTO TEST.SP500.SP_500
SELECT TOP 1 'TEST', 'TEST', 'TEST', '2023-01-29', * EXCLUDE (COMPANY_NAME, TICKER, DOMAIN, DATE)
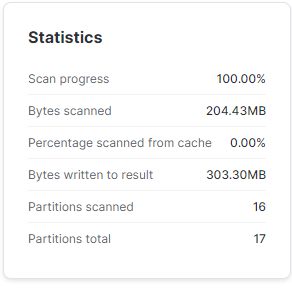
FROM TEST.SP500.SP_500;Wykonując prosty SELECT * FROM TEST.SP500.SP_500 zauważymy w statystykach wykonania, że zgodnie z powyższą teoria Snowflake stworzył nową mikro-partycję. Silnik bazy zeskanował jednak jedynie 16 z 17 partycji, a zawdzięczamy to metadanym. Snowflake wie, że ostatnia partycja składa się jedynie z 1 wiersza, więc nie ma potrzeby jej skanować, bo wszystkie dane może pobrać z samych metadanych.
Na podstawie powyższego, gdy będziemy chcieli pobrać wiersze jedynie z datą '2023-01-29' Snowflake nawet nie skorzysta z czytania partycji – odczyta zawartość tego wiersza z metadanych.
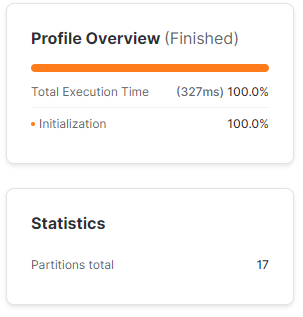
Ciekawie zaczyna się robić, jak dopiszemy do bazy kolejny wiersz, który będzie duplikatem tego, dla którego Snowflake stworzył nową partycję.
INSERT INTO TEST.SP500.SP_500
SELECT *
FROM TEST.SP500.SP_500 WHERE DATE = '2023-01-29';Wyszukując ponownie wiersze z daty '2023-01-29' zauważymy 2 rzeczy:
- Zamiast utworzyć nową mikro-partycję Snowflake „dopisał” nowy wiersz do już istniejącej
- tak by się mogło wydawać, ale biorąc pod uwagę niemutowalność partycji najprawdopodobniej oznaczył poprzednią jako nieaktualną i stworzył nową zawierającą 2 wiersze
- najprawdopobniej jest to spowodowane zasadą, że mikro-partycje zawierają dane o wielkości od 50 do 500 Mb, więc póki mikro-partycja nie osiągnie minimalnej wielkości kolejne wiersze będą „dopisywane” do niej. (niestety jest to tylko mój domysł – nie znalazłem żadnej wzmianki na ten temat w dokumentacji ani żadnych innych źródłach)
- Snowflake sprytnie wykorzystał metadane. Znów nie odczytywał partycji, ale odczytał wszystkie dane z metadanych (2 wiersze, dla których MIN, MAX i średnie są identyczne).
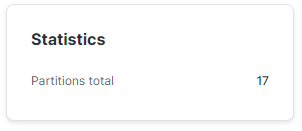
Dodajmy teraz kolejny wiersz, taki sam, jak ostatnio zapisane, ale z datą o dzień późniejszą.
INSERT INTO TEST.SP500.SP_500
SELECT TOP 1 'TEST', 'TEST', 'TEST', '2023-01-30', * EXCLUDE (COMPANY_NAME, TICKER, DOMAIN, DATE)
FROM TEST.SP500.SP_500 WHERE DATE = '2023-01-29';I wyszukajmy ponownie wierszy z 29 stycznia. Jak widać tym razem Snowflake już musiał zeskanować tę partycję w poszukiwaniu odpowiednich danych.
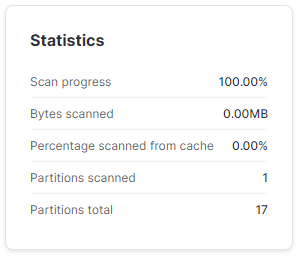
Dodawanie dużej liczby wierszy
Dodajmy tym razem milion testowych wierszy z datą '2022-02-31'.
INSERT INTO TEST.SP500.SP_500
SELECT TOP 1000000 'TEST', 'TEST', 'TEST', '2023-01-31', * EXCLUDE (COMPANY_NAME, TICKER, DOMAIN, DATE)
FROM TEST.SP500.SP_500;Wyszukując wiersze z nową datą Snowflake elegancko odczytał dane jedynie z 8 spośród już 24 partycji.
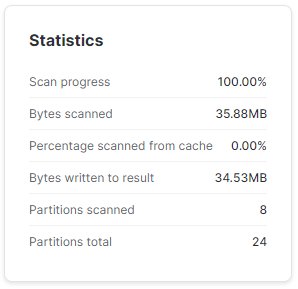
A teraz ciekawostka. Wszystkie wiersze, jakie dopisaliśmy do tabeli miały w kolumnie COMPANY_NAME wpisaną wartość 'TEST'. Można by przypuszczać, że skoro tabela była pierwotnie podzielona na 16 mikro-partycji i dopisując nowe wiersze utworzyło się łącznie nowych 8 mikro-partycji, a tylko nowe wiersze mają wartość 'TEST', to wyszukując dane z predykatem COMPANY_NAME = 'TEST' Snowflake efektywnie wykorzysta metadane tabel i odczyta jedynie nowe partycje.
Niestety nic z tego. Metadane partycji nie przechowują wszystkich wartości kolumn, jakie są zawarte w każdej mikro-partycji. Metadane zawierają jedynie podstawowe statystyki (wspomniane wcześniej minimum, maksimum itp.). Ze względu na dużą różnorodność nazw firm w tej kolumnie i posortowanie danych po dacie nie umożliwia pominięcie skanowania partycji w tym przypadku.
Można jednak zaobserwować po ilości zeskanowanych bajtów, że Snowflake efektywnie wykorzystuje swoją architekturę kolumnową i zamiast skanować całą tabelę, to przeskanował kolumnę COMPANY_NAME przez wszystkie partycje, ale resztę kolumn pobrał jedynie z partycji, które spełniały wymagania zapytania.
Update & Delete a mikro-partycje
Tutaj w praktyce dużo nie zobaczymy zmiany w mikro-partycjach, ale możemy trochę poczarować. Na początek zmieńmy COMPANY_NAME na '0-TEST' dla wszystkich wierszy z datą '2023-01-31'.
UPDATE TEST.SP500.SP_500
SET COMPANY_NAME = '0-TEST'
WHERE DATE = '2023-01-31';SELECT *
FROM TEST.SP500.SP_500
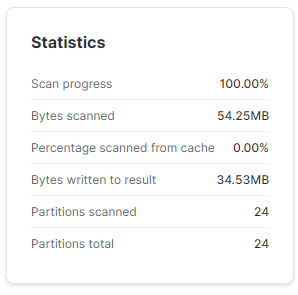
WHERE COMPANY_NAME = '0-TEST';Jak widać poniżej Snowflake zaktualizował milion wierszy. Nowa nazwa firmy jest na tyle selektywna, że baza mogła pominąć odczytywanie partycji, w których tej nazwy na pewno nie ma.
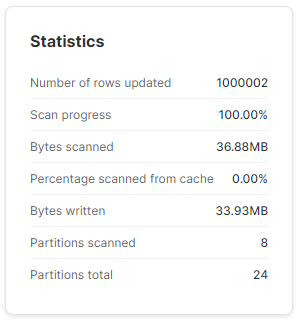
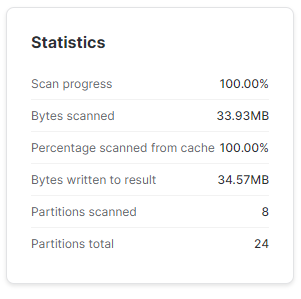
Zróbmy teraz odrobinę zamieszania – dodamy nowy wiersz z datą '2023-02-01'. Zgodnie z oczekiwaniem Snowflake dodał nam nową mikro-partycję.
INSERT INTO TEST.SP500.SP_500
SELECT TOP 1 'TEST', 'TEST', 'TEST', '2023-02-01', * EXCLUDE (COMPANY_NAME, TICKER, DOMAIN, DATE)
FROM TEST.SP500.SP_500
WHERE DATE = '2023-01-31';SELECT *
FROM TEST.SP500.SP_500
WHERE DATE = '2023-02-01';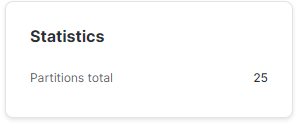
Teraz zaktualizujemy wszystkie wiersze z datą po '2023-01-30'.
UPDATE TEST.SP500.SP_500
SET COMPANY_NAME = 'TEST'
WHERE DATE > '2023-01-30';SELECT *
FROM TEST.SP500.SP_500
WHERE DATE = '2023-02-01';Jak widać w statystykach, znów mamy 24 partycje. Oznacza to, że Snowflake przeprowadzając aktualizację danych (odtwarzając mikro-partycje ze zaktualizowanymi danymi) jest w stanie do pewnego stopnia zoptymalizować partycje i usunąć te zbyt małe.
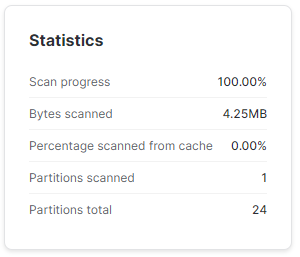
Z poleceniem DELETE nie wymyślę nic ciekawszego ponad to, że mogę usunąć wszystkie dane po '2022-01-30′ i udowodnić, że liczba partycji tej tabeli znacznie spadnie.
DELETE FROM TEST.SP500.SP_500
WHERE DATE > '2023-01-30';SELECT *
FROM TEST.SP500.SP_500
WHERE DATE = '2022-01-30';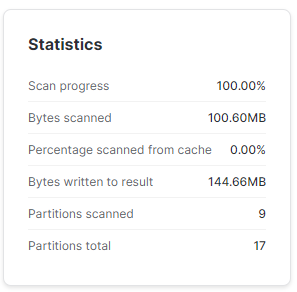
Podsumowanie
Kluczowe elementy przy zapisywaniu danych do bazy kolumnowej w kontekście przyszłej wydajności zapytań:
- Kolejność zapisywanych danych.
- Najlepiej, żeby były zapisywane w kolejności najczęściej wykorzystywanych filtrów.
- Wielkość pojedynczego wsadu.
- Im większy wsad zapisywanych danych tym lepiej baza może podzielić go na mikro-partycje.
Ponadto warto pamiętać, że polecenie UPDATE i DELETE nie zmieniają danych w miejscu. Silnik bazy zamiast tego, oznacza starą mikro-partycję jako nieaktualną i odtwarza ją od nowa z nowymi wartościami lub bez usuniętych kolumn. Są to operacje dość nieefektywne w bazach analitycznych.
Dodaj komentarz