Żeby efektywnie korzystać z baz kolumnowych, takich jak Snowflake, kluczowe jest zrozumienie jak one przechowują dane. Przedstawię to na podstawie wspomnianego Snowflake’a. Architektura kolumnowa jednak działa praktycznie tak samo we wszystkich bazach kolumnowych jak i indeksie columnstore w MS SQL Server.
Jeśli wiesz już jak tabele są materializowane w bazach kolumnowych zajrzyj też do wpisu, gdzie opisałem podstawowe rodzaje tabel w Snowflake’u.
Teoria
Dla uproszczenia przykład przedstawię na małej tabeli transakcji z 6 wierszami. Poniżej widać podział tabeli na 2 mikro-partycje, które nie muszą być jednakowej wielkości.
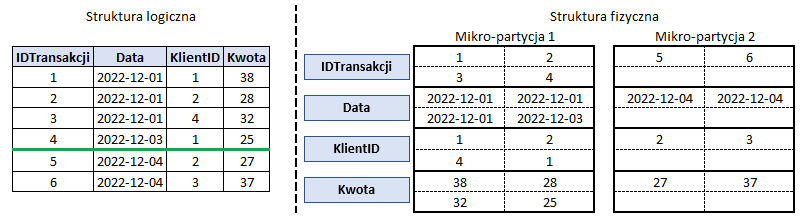
Cechy mikro-partycji:
- Na każdą z partycji przypada od 50 do 500 Mb danych (przed kompresją – Snowflake automatycznie kompresuje wszystkie partycje).
- Każda partycja reprezentuje zestaw wierszy z całej tabeli i dzieli się na bloki reprezentujące poszczególne kolumny.
- IDTransakcji
- Data
- KlientID
- Kwota
- Dzięki blokowemu przechowywaniu kolumn Snowflake może każdą z kolumn skompresować dobierając optymalny sposób kompresji.
- Każda partycja ma przypisane tzw. Header, który zawiera metadane o niej i wierszach kolumn, jakie zawiera (liczba wierszy, maksymalne i minimalne wartości itd).
Bazy kolumnowe, dzięki składowaniu każdej kolumny osobno i metadanych o każdej z mikro-partycji pozwalają na pomijanie partycji, które nie zawierają danych, które nas interesują. Wybierając tylko część kolumn zamiast wszystkich pomijane są też wartości kolumn, których nie potrzebujemy. Znacząco zwiększa to wydajność zapytań, jak również zmniejsza koszty związane z odczytywaniem danych.
Korzyści z orientacji kolumnowej:
- Dzięki podziale struktury tabeli na mikro-partycje filtrując dane optymalizator Snowflake’a najpierw sczytuje metadane o partycjach i czyta tylko z tych, które zawierają interesujące nas dane.
- Dzięki blokowej strukturze partycji (każda kolumna w oddzielnym bloku) Snowflake jest w stanie pominąć kolumny, których nie wybraliśmy w kwerendzie.
Praktyka
Praktyczny przykład zaprezentuję na podstawie tabeli SP_500 ze zbioru „S & P 500 by domain and aggregated by tickers (Sample)”. Zbiór jest dostępny za darmo w Snowflake Marketplace. Żeby mieć wgląd w pełne statystyki tabeli i wykonywanych zapytań utworzyłem kopię tabeli SP_500 na lokalnej przestrzeni dla mojego konta w Snowflake’u.
CREATE TABLE TEST.SP500.SP_500
AS SELECT *
FROM SP500_BY_DOMAIN.DATAFEEDS.SP_500
ORDER BY DATE;Klauzula ORDER BY jest bardzo ważna w tym przypadku. Snowflake dzieli tabelę na mikro-partycje automatycznie, ale na podstawie kolejności danych, jakie zapisuje na bieżąco. Dzięki uszeregowaniu danych od najstarszych do najnowszych partycje tabeli będą podzielone optymalnie – w kolejności ich tworzenia.
Snowflake umożliwia wgląd w metadane dotyczące ilości partycji w tabeli na kilka sposobów:
- wykonując zapytanie do tabeli możemy się tego dowiedzieć ze statystyk dostępnych w historii
- wykorzystując polecenie
SYSTEM$CLUSTERING_INFORMATION, które nie tylko poda liczbę partycji, ale też dowiesz się o poziomie klastrowania.
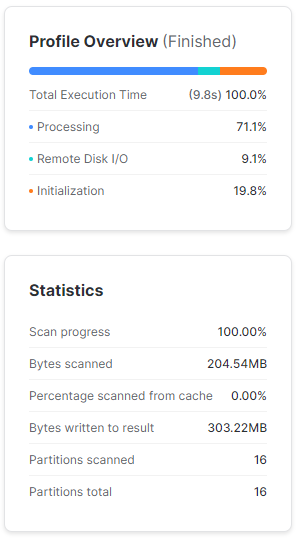
Wykonując SELECT * FROM TEST.SP500.SP_500 dostaniemy spodziewany wynik, zawierający wszystkie kolumny i skanujący wszystkie dane.
W statystykach zapytania widać, że Snowflake podzielił tabelę na 16 partycji. Wyświetlił ponad 300Mb danych pomimo, że przeskanował 204 Mb. Wynika to z kompresji danych, o której wspomniałem wcześniej. Snowflake jest w stanie efektywnie kompresować dane i odczytywać je ze skompresowanych plików.
Zawęźmy teraz wyniki zapytania jedynie do daty od 2020-01-01. W tym przypadku Snowflake pominął skanowanie 8 partycji, które nie zawierają danych sprzed 2020 roku. Te mikro-partycje, które zeskanował, miały zaledwie niecałe 103 Mb. Widać też oszczędność czasu w wykonaniu zapytania – 5,7 s względem 9,8 s.
SELECT *
FROM TEST.SP500.SP_500
WHERE DATE >= '2020-01-01';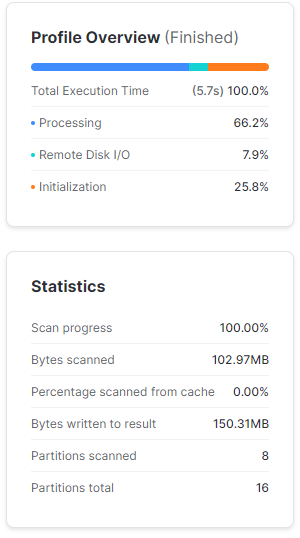
Zawęźmy zapytanie do kilku kolumn – tutaj widać moc baz kolumnowych. Jeśli przyjdzie nam wyciągać dane z wielokolumnowej tabeli, zamiast czytać całe wiersze, Snowflake jest w stanie pominąć kolumny, których nie potrzebujemy. Ograniczając zapytanie do kilku kolumn Snowflake przeskanował zaledwie 20 Mb danych, co przełożyło się to na znaczne skrócenie czasu wykonywania zapytania.
SELECT DATE, COMPANY_NAME, TICKER, TOTAL_VISITS
FROM TEST.SP500.SP_500
WHERE DATE >= '2020-01-01';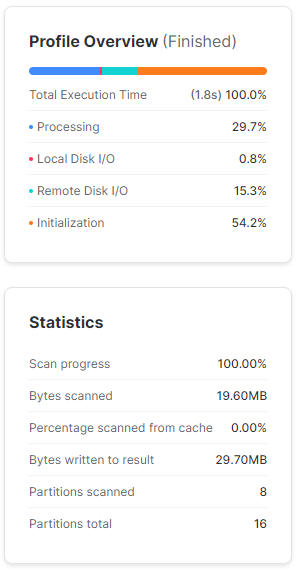
Podsumowanie
Optymalne wykorzystanie architektury fizycznego przechowywania danych w bazach kolumnowych zaczyna się już od sposobu stworzenia tabeli. Zazwyczaj głównym kluczem filtrującym jest zakres dat, więc jeśli tabela będzie zapisywała kolejne dane to warto, żeby były one posortowane po dacie. Umożliwi to optymalne tworzenie mikro-partycji.
Ogromną zaletą bazy kolumnowej jest możliwość pomijania danych kolumn, których nie potrzebujemy, więc najlepiej unikać zapytań typu SELECT *, gdyż powodują konieczność skanowania wszystkich kolumn.
- Tworząc tabele dbaj o kolejność zapisywanych danych.
- Ograniczaj liczbę wyszukiwanych rekordów.
- Wybieraj jedynie niezbędne kolumny.
Dodaj komentarz