W 2023 roku Snowflake wprowadził sporo ciekawych funkcjonalności upraszczających życie przy pisaniu prostszych i bardziej skomplikowanych zapytań. Z parametrów do SELECT * wiedziałem już wcześniej i z radością korzystałem, a o pozostałych dowiedziałem się podczas konferencji Snowflake BUILD 2023 w Warszawie.
- Parametry dla SELECT *
- ILIKE
- EXCLUDE
- REPLACE
- RENAME
- Funkcje agregujące:
- MIN_BY
- MAX_BY
- GROUP BY ALL
- Zaokrąglenia bankierskie (gaussowskie)
- Funkcje szeregów:
- ARRAY_SORT
- ARRAY_MAX
- ARRAY_MIN
Parametry dla SELECT *
Snowflake przedstawił w tym roku 4 świetne rozszerzenia do wykorzystania w połączeniu z SELECT * (którego jak wiesz należy unikać :).
ILIKE
ILIKE pozwala wyfiltrować spośród wszystkich dostępnych kolumn te, które pasują do wzorca.
W poniższym przykładzie wyświetlam klucz produktu i wszystkie kolumny zawierające słowo „ship”.
select l_orderkey
, * ILIKE '%ship%'
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM;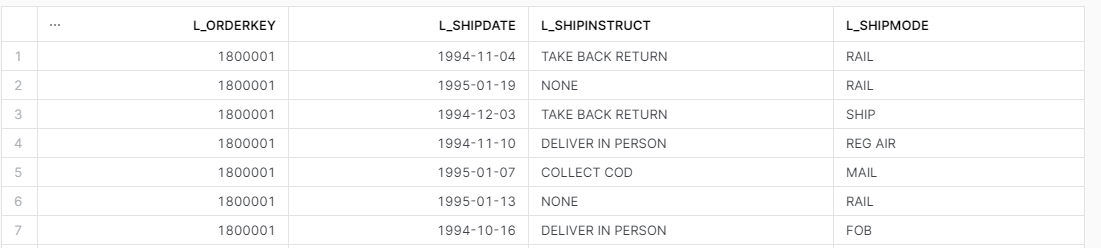
EXCLUDE
Jeśli masz sytuację, że tabela zawiera dużą liczbę kolumn i rzeczywiście potrzebujesz niemal wszystkich dobrym rozwiązaniem będzie właśnie EXCLUDE. Zamiast wymieniać wszystkie kolumny, których potrzebujesz możesz napisać SELECT * EXCLUDE (lista kolumn, których nie potrzebujesz).
W poniższym przykładzie biorę wszystkie kolumny z tabeli CUSTOMER oprócz c_acctbal, c_mktsegment i c_comment.
select * EXCLUDE (c_acctbal, c_mktsegment, c_comment)
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;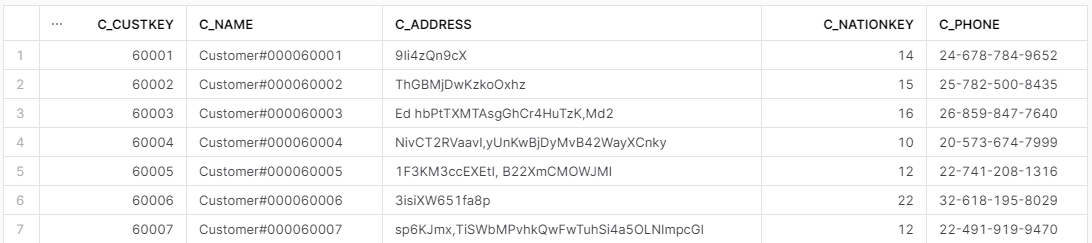
REPLACE
REPLACE pozwala podmienić w miejscu dowolnych kolumn istniejących już w tabeli inne wartości. Możesz przetransformować wartości tych kolumn, lub podmienić wartości na zupełnie inne.
W poniższym przykładzie wykorzystuję EXCLUDE i REPLACE na raz, by pokazać, że możemy wykorzystać te parametry w jednym zapytaniu.
Z kolumny c_name chcę zostawić jedynie 9-cio cyfrowy numer a w miejscu kolumny c_phone podstawiam ten sam numer telefonu do wszystkich klientów (hehe).
select * EXCLUDE (c_acctbal, c_mktsegment, c_comment)
REPLACE (right(c_name,9) as c_name, '123-456' as c_phone)
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;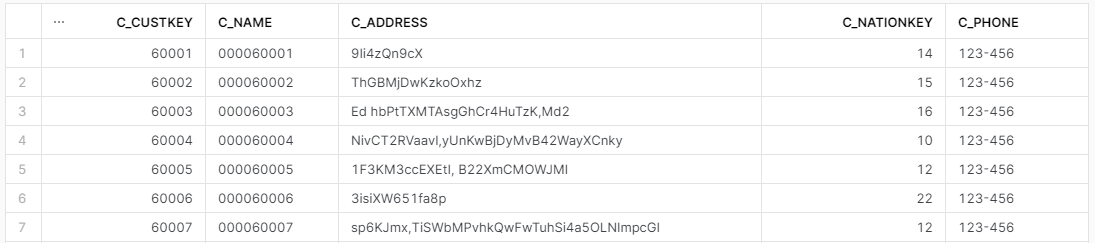
RENAME
Tutaj łatwo się domyślić, że to prosty sposób na zamianę nazwy wybranych kolumn. Idealnie mi się przydał przy tabeli przestawnej zakodowanej w makrze z dbt, gdzie część kolumn potrzebowałem nazwać inaczej niż ogólny wzorzec.
Poniżej podmieniam nazwę kolumny c_address na nową: random_characters.
select * EXCLUDE (c_acctbal, c_mktsegment, c_comment)
RENAME (c_address as random_characters)
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;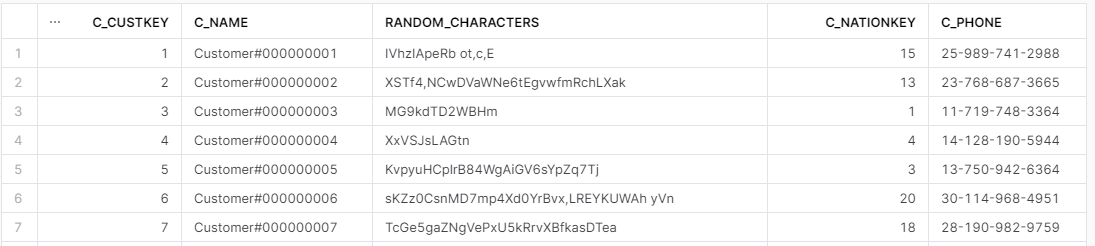
Podsumowując parametry SELECT *
Szczególnie EXCLUDE i RENAME są bardzo przydatne przy pracy z dużą liczbą kolumn i pomagają zachować kod bardziej zwięzły i czytelny.
Można wykorzystywać je w pojedynczym SELECT’cie, ale z pewnymi ograniczeniami:
- Nie możesz wykorzystać ILIKE i EXCLUDE razem
- Musisz zachować z góry określoną kolejność:
- ILIKE lub EXCLUDE
- REPLACE
- RENAME
Funkcje agregujące
MIB_BY i MAX_BY to nowe funkcje agregujące, które znajdują wiersz z minimalną lub maksymalną wartość w kolumnie i zwracają wartość z innej kolumny.
Jak widzisz w poniższym przykładzie, funkcja działa wyśmienicie.
Pierwszy parametr funkcji to kolumna, którą Snowflake ma zwrócić do wyniku.
Drugi parametr to kolumna, w której Snowflake szuka wartości minimalnych lub maksymalnych.
Możesz dodać jeszcze trzeci, opcjonalny, parametr, gdzie określisz ile wartości ma funkcja zwrócić do wyniku. Jeśli wartość minimalna/maksymalna powtarza się więcej niż 1 raz, to Snowflake zwróci listę zawierającą tyle wyników, ile jest wierszy z minimalną/maksymalną wartością, ale nie więcej niż wartość parametru.
select l_orderkey
,min(l_shipdate) as first_ship_date
,min_by(p_name,l_shipdate) as first_shipped_part
,max(l_shipdate) as last_ship_date
,max_by(p_name,l_shipdate) as last_shipped_part
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM l
join SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.PART p
on l.l_partkey = p.p_partkey
group by all
order by 1;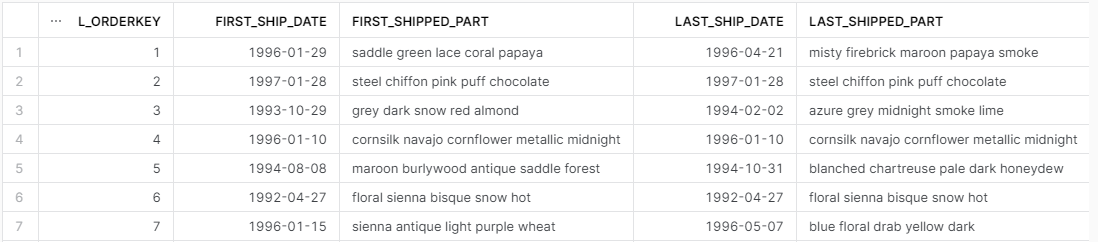
GROUP BY ALL
Chyba moja ulubiona funkcjonalność. Jak tworzę tabele zawierające zagregowane dane do wielu wymiarów dość uciążliwe staje się wymienianie wszystkich kolumn lub listowanie numerów kolumn, w których znajdują się wymiary. Jeszcze uciążliwsze staje się to w momencie edycji tej tabeli i dodawaniu bądź usuwaniu niektórych wymiarów.
GROUP BY ALL pozwala prawie całkowicie zapomnieć o tym bólu i skupić się na samych wymiarach, metrykach i logice biznesowej bez konieczności utrzymywania „sekcji grupującej”.
select o_orderstatus
,o_orderdate
,o_clerk
,count(*) as order_count
,sum(o_totalprice) as total_price
from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
group by all;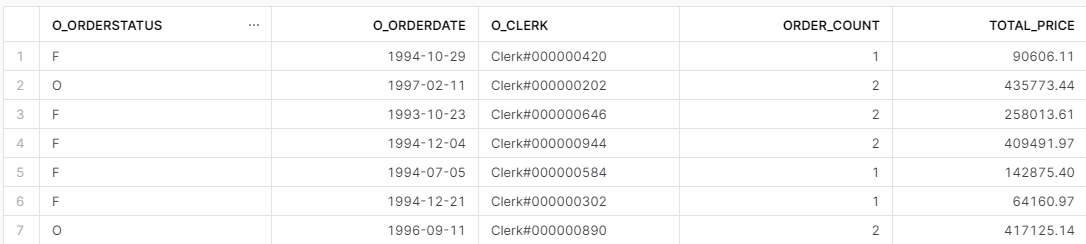
Zaokrąglenia bankierskie (gaussowskie)
Funkcja prawdopodobnie dobrze znana wszystkim pracownikom banków i osobom pracującym z bazami danych Oracle. Zaokrąglenia bankierskie różnią się od zaokrągleń matematycznych specjalnym traktowaniem równych połówek. Każda równa połówka jest zaokrąglana do najbliższej parzystej liczby.
0.5 => 0
1.5 => 2
Wszelkie pozostałe ułamki są traktowane identycznie, jak przy zaokrąglaniu matematycznym. Poniżej przykład z porównaniem do matematycznego zaokrąglenia.
select $1
,round($1)
,round($1,0,'HALF_TO_EVEN')
,round($1,1,'HALF_TO_EVEN')
from values (1.1)
,(1.5)
,(-1.5)
,(-0.5)
,(2.5)
,(2.55)
,(2.51);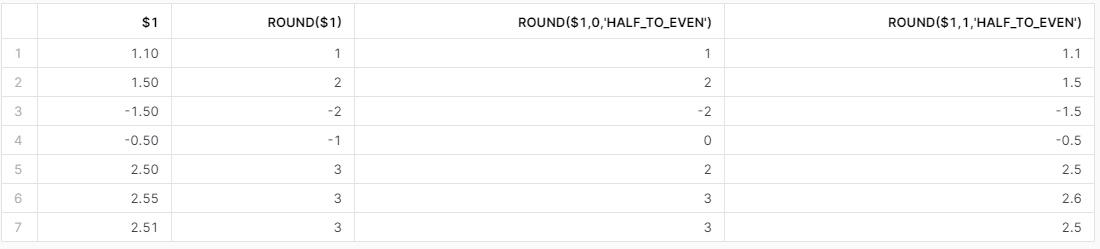
Funkcje szeregów
Jeśli pracujesz z danymi źródłowymi zawierającymi listy i krotki, to prawdopodobnie te funkcje mogą Ci się przydać.
ARRAY_SORT
ARRAY_SORT jako argument przyjmuje listę wartości i zwraca ją posortowaną rosnąco lub malejąco. Umożliwia też ustalenie, czy wartości NULL mają być na początku, lub na końcu.
Kolejność argumentów:
- Lista źródłowa
- Kolejność sortowania
- TRUE => rosnąco
- FALSE => malejąco
- NULLS First
- TRUE => NULL zostanie zwrócony jako undefined na początku listy
- FALSE => NULL jako undefined na końcu listy
select array_sort([1, 3, 2, 0, -15, NULL, 10, 134, -51], TRUE, FALSE);
Warto mieć na uwadze, że zwrócona posortowana lista może zawierać niespodziewany rezultat w przypadku listy zawierającej różne typy wartości (timestamp, real, JSON).
ARRAY_MIN i ARRAY_MAX
Obie funkcje są raczej dość intuicyjne. Tak samo, jak ARRAY_SORT operują oczywiście na listach a ich zadaniem jest znalezienie pojedynczej najmniejszej lub największej wartości. Zarówno ARRAY_MIN jak i ARRAY_MAX pomijają całkowicie wartości NULL, jednak jeśli lista będzie składała się jedynie z NULLi, to siłą rzeczy również zwrócą NULL.
select array_min([1, 3, 2, 0, -15, NULL, 10, 134, -51]);
select array_max([1, 3, 2, 0, -15, NULL, 10, 134, -51]);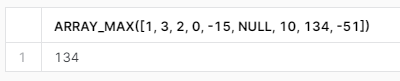
Dodaj komentarz